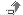|
Технология Клиент-Сервер 2002'3
|
|
|
Новое в СУБД ЛИНТЕР 6.1
Петр Лысачев (lisachev@relex.ru),
Виталий Максимов (vitamax@relex.ru),
Михаил Ермаков (ermakov@relex.ru)
Этой осенью ожидается выход на рынок новой версии
отечественного SQL-сервера ЛИНТЕР.
Новая версия системы существенно отличается от своей
предшественницы, причем изменения затронули не только сервисные средства СУБД,
но и ядро системы.
Среди новых возможностей ядра системы стоит отметить
поддержку многоверсионности данных, внутреннее резервное сохранение баз данных (in-kernel
backup), улучшения системы репликации и возможность получения планов исполнения
запросов. Были добавлены новые типы данных, введены национальные многобайтовые
кодировки. Помимо этого, велась работа по переносу СУБД на другие платформы, в
частности QNX RTP (QNX 6),WinCE, OС 2000. Для более удобной работы с СУБД на PDA
было разработано средство синхронизации баз данных RelXSync.
В сервисных средствах ориентация была сделана на разработку
межплатформных графических утилит, функционирующих как в Win32, так и в
UNIX-подобных ОС. Были разработаны первые версии утилит для администрирования
СУБД, сохранения и восстановления баз данных, тестирования баз данных, миграции
данных.
Большое внимание было уделено развитию различных интерфейсов
и конвертеров данных. Были разработаны или получили значительные изменения
драйвера DBExpress, OLE DB Provider, NATIVE ODBC for PHP, UNICODE ODBC driver.
В общем, за прошедший год разработчики проделали большую
работу. В настоящее время заканчивается подготовка выхода на рынок шестой версии
СУБД ЛИНТЕР. В данной статье мы попытаемся обозначить основные черты этой
системы.
Новые RT-OC
XXI-й век не зря называют веком информационных технологий.
Каждый день обрушивает на нас такое количество информации, что человек просто не
в силах с ней справиться. Появление карманных компьютеров (КПК) позволило
автоматизировать хранение и анализ информации, находящейся «в кармане». Эти
устройства год от года становятся все более популярными.
Но если есть устройство, предназначенное для работы с
данными, должно быть и программное обеспечение, облегчающее эту работу. Сегодня
СУБД ЛИНТЕР уже реально функционирует под ОС Microsoft Windows CE. СУБД ЛИНТЕР
для Windows CE, несмотря на жесткие требования, налагаемые аппаратурой КПК,
является полноценным SQL-сервером и ни в чем не уступает системам, работающим на
"больших" компьютерах.
Впрочем, присутствие СУБД ЛИНТЕР на КПК не ограничивается
только Windows CE. Так же поддерживается Linux на КПК Sharp Zaurus. В ближайших
планах компании РЕЛЭКС перенос СУБД ЛИНТЕР на ОС EPOC компании Symbian,
устанавливаемой в таких устройствах, как "умные телефоны" (smart phones).
Предыдущие версии ЛИНТЕР поддерживали системы реального
времени VxWorks, QNX 4 RTOS и отечественную ОС реального времени ОС 2000. ЛИНТЕР
6.0, кроме перечисленных систем, поддерживает еще и новую версию ОС QNX Neutrino
RTOS v6.
СУБД ЛИНТЕР уже давно позволяла создавать многопоточные
приложения для ОС Windows. В новой версии ЛИНТЕР эта возможность реализована
также для Unix и QNX. Для этого в состав дистрибутива включены специальные
версии интерфейсов intlib и linapi, поддерживающие потоки POSIX. В ближайшее
время поддержка многопоточных приложений будет реализована для ОС Linux,
Solaris, FreeBSD, QNX v6 и других систем, поддерживающих потоки POSIX.
В настоящее время заканчивается работа над разработкой новых
графических утилит для Unix-систем. В версию 6.1 планируется включить следующие
инструменты:
-
утилиту "горячего" (без останова работы ядра СУБД)
архивирования базы данных lhbx;
-
утилиту сохранения и восстановления базы данных (и
отдельных элементов БД) в текстовом формате;
-
утилиту тестирования базы данных;
-
новый графический "рабочий стол" ЛИНТЕР, ранее
поставлявшийся только в составе Windows-версий.
Многоверсионность
С версии 6.0 ЛИНТЕР становится многоверсионной СУБД.
Многоверсионная СУБД – это система, основанная на многоверсионной модели данных.
Основными понятиями являются: “логическая” запись – запись,
видимая клиентской задаче, и “физическая” запись – единица хранения набора полей
в таблице.
В отличие от предыдущих версий, в которых каждая запись
существовала в единственном экземпляре, в СУБД ЛИНТЕР 6.1 реализована
многоверсионная структура данных, позволяющая изолировать транзакции без
наложения блокировок на нефиксированные данные. Каждая “логическая” запись,
видимая клиентской задаче, в таблице представлена набором “физических” записей.
Эти “физические” записи собраны в односвязные списки
(цепочки). Все элементы списка (версии) имеют один и тот же “логический” номер (ROWID).
Клиентская задача “видит” именно эти логические номера.
В списке “физические” записи упорядочены по времени их
создания. Каждый элемент имеет информацию о времени его создания и номере
соединения, создавшего его. Удаление “логической” записи приводит к порождению
новой версии записи, помеченной как “удаленная”.
В файле индексов индексы также сгруппированы по
принадлежности к одной и той же “логической” записи. Следует отметить, что
модификация любого поля “логической” записи приводит к порождению новой версии,
а, следовательно, и индекса в индексном файле. Старые элементы списков
“физических” записей, не используемые транзакциями – это "мусор". Для удаления
"мусора" существует специальная процедура – очистка таблицы. Возможна также
фоновая очистка таблицы от старых версий. Этим занимается так называемый процесс
очистки.
Кроме того, при модификации “логической” записи цепочка
сканируется на предмет наличия в ней старой версии, и если такая существует, она
используется повторно. Это значит, что при условии отсутствия “длинных”
транзакций цепочки записей не разрастаются безгранично. BLOB-файлы также
содержат версии BLOB, принадлежащие разным версиям “логической” записи.
Иерархия каналов и конкуренция каналов
В ЛИНТЕР 6.1 реализована двухуровневая иерархия каналов:
соединения и принадлежащие им курсоры (подчиненные каналы).
В отличие от предыдущих версий СУБД ЛИНТЕР, в которых
конкурирующей единицей считался процесс, теперь единица конкуренции –
соединение.
Т.е. в рамках одного процесса несколько соединений могут
конкурировать друг с другом. Это может приводить к взаимным блокировкам.
Следовательно, прикладная задача, использующая несколько соединений для доступа
к общему набору данных, должна учитывать возможность взаимной блокировки
соединений.
Курсоры одного соединения не конкурируют друг с другом. Это
контексты выполнения запросов в рамках одного соединения. Нефиксированные
изменения, сделанные любым из курсоров в соединении, видны остальным курсорам
этого соединения. При этом любой курсор соединения может менять нефиксированные
данные другого курсора этого же самого соединения.
В ЛИНТЕР 6.1, в отличие от предыдущих версий, нет отдельного
режима работы, называемого AUTOCOMMIT. Этот режим обладал отдельным
(относительно режимов EXCLUSIVE и OPTIMISTIC) алгоритмом работы с журналом.
Считалось, что режим AUTOCOMMIT – это не транзакционный режим.
Теперь время жизни каждого канала от момента его открытия до
момента закрытия разбито на несколько транзакций. Первая транзакция начинается в
момент открытия канала. Следующие транзакции начинаются только после завершения
предыдущей транзакции.
В новой версии существует специальный модификатор режима
работы канала – AUTOCOMMIT. Этот режим логически соответствует AUTOCOMMIT в
предыдущих версиях СУБД ЛИНТЕР. Если канал открывается с таким модификатором, то
каждый DML-запрос неявно вызывает завершение транзакции. Режим AUTOCOMMIT можно
выключать и отключать с помощью SQL запроса:
SET CHANNEL AUTOCOMMIT {ON|OFF};
В ЛИНТЕР 6.1 введено два режима работы канала по отношению к
конфликтам с другими каналами. Это блокирующий и неблокирующий режимы работы
канала. Если канал находится в блокирующем режиме работы, то конфликт с
нефиксированными данными, сделанными конкурирующим соединением, приведет к
приостановке канала до завершения конкурирующей транзакции.
Если канал находится в неблокирующем режиме работы, конфликт
с нефиксированными данными, сделанными конкурирующим соединением, приведет к
немедленной выдаче ошибки, что ДАННЫЕ БЫЛИ МОДИФИЦИРОВАНЫ (ИЛИ УДАЛЕНЫ)
КОНКУРИРУЮЩЕЙ ТРАНЗАКЦИЕЙ (8104).
При открытии канал находится в блокирующем режиме. Чтобы
изменить режим работы канала, надо подать следующий SQL запрос:
SET CHANNEL {WAIT | NOWAIT}
где WAIT задает блокирующий, а NOWAIT – не блокирующий режим
работы канала.
Замечание 1: Запросы на модификацию режимов работы
каналов должны быть первыми в канале после начала транзакции (до любых
DML-запросов). Если запрос на изменение режима подан после DML-запроса, он
вернет ошибку НЕВЕРНАЯ ПОСЛЕДОВАТЕЛЬНОСТЬ КОМАНД (1013).
Замечание 2: Открываемый курсор наследует текущий режим
работы соединения. Смена режима работы соединения не влияет на режимы работы
открытых ранее курсоров.
Уровни изоляции транзакций
В ЛИНТЕР 6.1 реализовано четыре уровня изоляции транзакций:
READ UNCOMMITTED(1), READ COMMITTED(2), SERIALIZABLE(3), OPTIMISTIC(4) (оставлен
для совместимости с предыдущими версиями СУБД). Следует отметить, что в отличие
от предыдущих версий, выборка стабильна при любых уровнях изолированности
транзакций.
READ_UNCOMMITTED
При работе в этом режиме транзакция видит все свои изменения и изменения,
сделанные транзакциями уровней 1-3 (фиксированные и нефиксированные).
Транзакция не видит нефиксированных изменений, внесенных OPTIMISTIC
транзакцией. Выборка стабильна. Транзакция не может менять данные, измененные
и не фиксированные другими транзакциями. При попытке сделать это запрос будет
либо ждать завершения конкурирующей транзакции, либо выдаст сообщение об
ошибке, говорящее, что данные были изменены (в зависимости от того, какой
режим работы канала выбран – блокирующий или неблокирующий). При попытке
создать/модифицировать/удалить запись так, что происходит конфликт ссылочной
целостности с нефиксированными данными, сделанными другими транзакциями,
запрос будет либо ждать завершения конкурирующей транзакции, либо выдаст
сообщение об ошибке, говорящее, что данные были изменены. При попытке сделать
ссылку на нефиксированные данные (FK) запрос будет ждать завершения
конкурирующей транзакции или завершится ошибкой.
READ_COMMITTED
Транзакция видит все свои изменения и фиксированные изменения, сделанные
транзакциями уровней 1-4. Выборка стабильна. Транзакция не может изменять
данные, измененные и нефиксированные другими транзакциями. При попытке сделать
это, запрос будет либо ждать завершения конкурирующей транзакции, либо выдаст
сообщение об ошибке, говорящее, что данные были изменены (в зависимости от
того, какой режим работы канала выбран – блокирующий или неблокирующий). При
попытке создать/модифицировать/удалить запись так, что происходит конфликт
ссылочной целостности с нефиксированными данными, сделанными другими
транзакциями, запрос будет либо ждать завершения конкурирующей транзакции,
либо выдаст сообщение об ошибке, говорящее о конфликте по ссылочной
целостности.
SERIALIZABLE
Транзакция видит все свои изменения и фиксированные изменения, сделанные
транзакциями уровней 1-4, которые завершились до ее старта. Выборка стабильна.
Транзакция не может менять данные, измененные и не фиксированные другими
транзакциями. При попытке сделать это запрос будет либо ждать завершения
конкурирующей транзакции, либо выдаст сообщение об ошибке. При попытке
создать/модифицировать/удалить запись так, что происходит конфликт ссылочной
целостности с нефиксированными данными, сделанными другими транзакциями,
запрос будет либо ждать завершения конкурирующей транзакции, либо выдаст
сообщение о конфликте по ссылочной целостности. При попытке модифицировать
данные, которые были модифицированы (удалены), причем эти изменения были
фиксированы после ее старта, запрос завершится ошибкой НЕСЕРИЙНЫЙ ДОСТУП К
ДАННЫМ (8102). Одновременно может существовать ограниченное число соединений с
режимом SERIALIZABLE (100). Попытка создать большее число соединений с режимом
SERIALIZABLE приведет к сообщению об ошибке "НЕТ СВОБОДНОЙ ТОЧКИ ВХОДА В
ТАБЛИЦЕ СЕРИЙНЫХ ТРАНЗАКЦИЙ (8107)".
OPTIMISTIC
Этот режим унаследован из предыдущих версий СУБД ЛИНТЕР. Транзакция видит
все фиксированные изменения, сделанные транзакциями уровней 1-4. Транзакция не
видит ни своих, ни чужих нефиксированных изменений. Выборка стабильна. При
попытке модифицировать/удалить запись так, что происходит конфликт ссылочной
целостности с данными, сделанными другими транзакциями, транзакция завершается
(откатывается) с ошибкой 1600. Если при фиксации транзакции происходит ошибка,
то транзакция откатывается.
Замечание 1: Проверка выполнимости условий ссылочной
целостности выполняется в момент исполнения запроса, а не в момент фиксации
транзакции.
Смена уровней изоляции
Уровень изоляции соединения может быть задан при его открытии
(как параметр функции “OPEN” CALL интерфейса) или с помощью SQL-запроса (см.
ниже), если это первый запрос в текущей транзакции. После первого же DML-запроса
изменить уровень изоляции нельзя.
При попытке сделать это запрос вернет ошибку НЕВЕРНАЯ
ПОСЛЕДОВАТЕЛЬНОСТЬ КОМАНД (1013). Уровень изоляции соединения по умолчанию –
READ COMMITTED с AUTOCOMMIT.
Смена уровня изоляции соединения с открытыми курсорами
приведет к смене уровней изоляции всех курсоров соединения (или к ошибке 1013,
если хотя бы по одному из них был подан ранее DML-запрос).
SQL-запросы, относящиеся к изоляции транзакций:
SET TRANSATION ISOLATION LEVEL {READ UNCOMMITTED| READ COMMITTED | SERIALIZABLE | OPTIMITIC};
Индексы
На момент создания индексов работа с таблицей
приостанавливается (таблица блокируется).
Индексы создаются только для самой новой версии записи. При
этом запросы, стартовавшие до построения индекса, не меняют своей стратегии до
их завершения.
Блокировки
Иногда возникает необходимость явного блокирования выборки (FOR
UPDATE или FOR BROWSE). Блокировки в ЛИНТЕР реализованы таким образом, что если
затребована блокировка “логической” записи, блокируется вся цепочка версий.
Ссылочная целостность и многоверсионность
В отличие от предыдущих версий, в СУБД ЛИНТЕР 6.1 имеется
возможность установить, является ли данная запись фиксированной. В связи с этим
произошли изменения в отношении проверок допустимости создания ссылок. В СУБД
ЛИНТЕР 6.1:
-
не могут быть созданы ссылки на нефиксированные данные,
созданные конкурирующими транзакциями других соединений;
-
могут быть созданы ссылки на нефиксированные данные,
созданные той же самой транзакцией;
-
могут быть созданы ссылки на нефиксированные данные,
созданные транзакциями по курсорам этого же соединения.
BLOB-данные
Ниже перечислены особенности работы с данными типа BLOB:
-
Добавление в BLOB.
-
Как и в предыдущих версиях СУБД ЛИНТЕР, добавление в BLOB
осуществляется с помощью команд ABOJ, ABLB. Но если в предыдущих версиях
вставка была “видна” конкурирующим транзакциям до фиксации транзакции,
произведшей ее, то теперь вставка видна (транзакциям с режимами выше READ
UNCOMMITTED) только после фиксации транзакции.
-
Очистка BLOB.
Как и в предыдущих версиях СУБД ЛИНТЕР, очистка BLOB
осуществляется командами COBJ, CBLB при этом реальная очистка страниц BLOB
происходит в момент фиксации транзакции.
Но при наличии конкурирующей SERIALIZABLE транзакции фиксация транзакции не
приводит с физической очистке страниц BLOB. Они только помечаются “к удалению”.
После того, как все SERIALIZABLE транзакции, стартовавшие до операции очистки
BLOB, завершатся, эти страницы могут быть переиспользованы для других BLOB.
Замечание 1: если две транзакции пытаются добавить в BLOB
некоторые данные или очистить BLOB, то для одной из них такая попытка завершится
ошибкой: ДАННЫЕ БЫЛИ МОДИФИЦИРОВАНЫ (ИЛИ УДАЛЕНЫ) КОНКУРИРУЮЩЕЙ ТРАНЗАКЦИЕЙ.
Приостановки выполнения запроса до завершения конкурирующей транзакции не
произойдет вне зависимости от текущего режима работы канала (блокирующий/неблокирующий).
Замечание 2: запрос на модификацию BLOB, поданный из
SERIALIZABLE-транзакции, завершится ошибкой: НЕСЕРИЙНЫЙ ДОСТУП К ДАННЫМ (8102),
если BLOB был модифицирован после начала этой транзакции.
Замечание 3: процесс очистки по возможности очищает
страницы BLOB, помеченные “к удалению”.
Очистка версий
Из-за того, что при конкурентной работе нескольких соединений
таблица оказывается заполненной версиями одной и той же записи, периодически
необходимо производить ее очистку – т.е. освобождение от старых неиспользуемых
версий.
Для этого существует специальный административный SQL-запрос:
PURGE TABLE <name> [ALL];
ALL используется в том случае, когда необходимо очистить
таблицу от старых записей полностью, вне зависимости от того, есть ли на данный
момент активные транзакции. Очистка таблицы с ключом ALL может привести к тому,
что активная SERIALIZABLE-транзакция, стартовавшая до очистки таблицы, увидит
изменение в наборе данных.
На время очистки таблица блокируется. Транзакции, пытающиеся
работать с этой таблицей, будут ждать завершения процесса очистки. Попытка
выполнить очистку таблицы, для которой уже запущен процесс очистки, приведет к
ошибке: ТАБЛИЦА УЖЕ В ОЧИСТКЕ (8114).
Изменения касаются режимов открытия канала. Введены следующие
режимы работы каналов:
-
M_READ_UNCOMMITTED – режим READ UNCOMMITTED
-
M_READ_COMMITTED – режим READ COMMITTED
-
M_SERIALIZABLE – режим SERIALIZABE.
Для совместимости с предыдущими версиями сохранен режим
M_EXCLUSIVE – то же самое, что M_READ_COMMITTED.
Внутреннее резервное сохранение базы данных
Полное резервное сохранение базы данных (далее – архивация) –
это физическое сохранение всей структуры и данных в файл архива.
Инкрементная архивация – это создание файла архива,
содержащего полную резервную копию базы данных с возможностью добавления к этому
файлу изменений, произошедших в базе данных со времени последней инкрементной
архивации.
В новой версии ЛИНТЕР появилась возможность внутренней
архивации. В отличие от сохранения базы данных, осуществляемого при помощи
утилиты lhb (Linter Hot Backup), внутренняя архивация осуществляется без участия
внешних утилит, собственно ядром СУБД ЛИНТЕР.
Кроме того, в системе реализована возможность синхронного
запуска процесса архивации базы данных. При таком запуске пользователь, подавший
команду на запуск процесса архивации, получает ответ (код возврата) от базы
только по окончании процесса. Естественно, что при этом необходимо наличие
соединения пользователя с базой данных в течение всего процесса сохранения.
Возможен также и асинхронный запуск процесса архивации базы
данных. При этом пользователь, подавший команду на запуск архивации, получает
ответ от базы данных сразу. В случае успешного старта, процесс архивации
работает в собственном канале. Соединение пользователя с базой данных в течение
всего времени архивации не требуется.
Особенности внутреннего резервного сохранения
Полная архивация осуществляется ядром СУБД без участия
дополнительных утилит. Для запуска этого процесса необходимо подать
соответствующий SQL-запрос. Полный синтаксис запроса можно найти в руководстве
пользователя "Внутреннее резервное сохранение базы данных СУБД ЛИНТЕР".
Такая реализация процесса архивации очень эффективна с точки
зрения удаленного администрирования системы или в том случае, когда нет
возможности использовать программу lhb. Создаваемый файл архива полностью
совместим с форматом, создаваемым при сохранении самой программой lhb.
С помощью SQL-запроса можно запустить только процессы полной
и инкрементной архивации. Восстановление базы из полученного архива придется
производить средствами программы lhb.
Сохранение осуществляется через определенные кванты времени и
не препятствует работе остальных каналов или пользователей системы. В ЛИНТЕР
возможна одновременная работа нескольких процессов внутреннего сохранения. Во
время работы процесса архивации файл архива открывается в эксклюзивном режиме,
т.е. модификация или удаление этого файла не допускается.
На данный момент в системе задано постоянное значение
одновременно открытых файлов архива. Это количество равно трем (в следующих
версиях СУБД ЛИНТЕР планируется реализовать возможность задания количества
одновременно открытых файлов через утилиту gendb при создании базы данных).
Примеры некоторых запросов на запуск процесса архивации
BACKUP DATABASE ASYNC FILE ‘File_name.lhb’ REWRITE COMMENT ‘Comment_to_archive_file’;
После подачи этого запроса будет запущен процесс создания
файла архива File_name.lhb (если таковой уже имелся на диске – он будет удален
без предупреждения), архивный файл будет создан с комментарием «Comment_to_archive_file».
Процесс будет проходить в асинхронном режиме, т.е. пользователь сразу получит
код возврата (0 – если процесс запустился), а процесс архивации будет протекать
независимо от того, находится ли пользователь, запустивший процесс в соединении
с базой. Желательно также запомнить возвращенное значение, соответствующее
номеру запущенного процесса, для того, чтобы впоследствии можно было легко
посмотреть, на какой стадии находится процесс резервного сохранения, и, если это
будет необходимо, для его останова.
BACKUP DATABASE DEVICE ‘SY00’FILE ‘not_async.lhb’ PASSWORD ‘password’;
После подачи этого запроса запустится процесс архивации в
файл not_async.lhb на устройстве SY00 (каталог базы данных). Если файл уже
существует, будет возвращен соответствующий код возврата и процесс прекратит
работу; если файл отсутствует, работа будет продолжена, и пользователь по ее
окончании получит соответствующий код возврата (0 – если процесс завершился
успешно). Данные в файле будут защищены введенным паролем ‘password’.
При резервном копировании возможно появление некоторых
проблем, связанных, как правило, с так называемым человеческим фактором, или,
проще говоря, с ошибками пользователей. В этом разделе мы попытаемся описать
основные ошибочные ситуации, возникающие при создании архива базы данных.
При написании запроса на создание архива пользователь по
какой-либо причине может неверно указать имя архивного файла. Например, указать
в качестве имени файла путь к исполняемому (или другому важному) файлу
операционной системы. Если при этом в SQL-запросе будет присутствовать команда
REWRITE, то этот файл будет удален перед созданием файла архива. Тем самым при
создании архива нарушится целостность либо операционной системы, либо любой
другой программы.
Чтобы избежать подобных ситуаций, перед процедурой удаления
указанного в SQL-запросе файла системой будет производиться проверка этого файла
по следующим критериям:
-
Это должен быть файл архива, созданный в результате
резервного сохранения либо программой lhb, либо в результате внутреннего
резервного сохранения.
-
Версия базы данных, с которой создавался архив, должна
совпадать с текущей версией СУБД ЛИНТЕР.
-
Имя пользователя, создавшего файл архива, должно совпадать
с именем пользователя, осуществляющего попытку перезаписи этого файла.
Исключение делается только для пользователя, создавшего базу данных (по
умолчанию – пользователь SYSTEM).
-
Имя файла не должно содержать абсолютного пути.
-
В имени не должно присутствовать каталогов и переходов на
уровень вверх на каталог (/../)
-
В качестве имени устройства должны выступать устройства,
описанные в системной таблице $$$DEVICE (либо устройство SY00). Совершенно
естественно, что необходимо наличие этой таблицы в базе данных.
Если указывается имя файла без имени устройства, сохранение
будет происходить в каталоге, на который указывает переменная SY00.
Примеры корректных имен файлов, передаваемых в SQL-запросе:
BACKUP DATABASE DEVICE ‘SY00’ FILE 'full_database.lhb';
BACKUP DATABASE DEVICE ‘SY02’ FILE 'another one archive.lhb'; (имя SY02 должно присутствовать в системной таблице $$$DEVICE).
BACKUP DATABASE FILE 'small.lhb'; (файл будет создан в пути, на который указывает SY00).
Примеры некорректных имен файлов, передаваемых в SQL-запросе:
BACKUP DATABASE FILE 'C:\full_database.lhb';
BACKUP DATABASE FILE 'SY00/ARCHIVES/database.lhb';
BACKUP DATABASE FILE '/../db.lhb';
Еще один важный момент – возможность истощения всего
дискового пространства операционной системы в результате создания большого файла
архива.
Останов процесса(ов) резервного сохранения, запущенных в асинхронном режиме
В случае необходимости, возможен принудительный останов
резервного сохранения при помощи sql-команды:
BACKUP STOP number;
Здесь number – номер, возвращенный после успешного старта
процесса архивации (по сути – RowId из таблицы $$$INKERNBACK, соответствующий
запущенному процессу). Либо:
BACKUP STOP ALL [SINCE <дата-время>] [UNTIL <дата-время>];
Эта команда позволяет соответственно остановить либо все
работающие в асинхронном режиме процессы архивации, либо все, подпадающие под
временные критерии. Результатом работы будет соответствующий код возврата в
случае неудачи попытки останова, либо нулевой код возврата в случае успеха.
Пользователю будет возвращено также число остановленных процессов.
Останавливать процессы архивации может либо тот пользователь,
который их запустил, либо пользователь с привилегиями DBA, имеющий право
останавливать любые активные процессы архивации (в том числе и других
пользователей).
Работа с кодовыми станицами
В версии 6 СУБД ЛИНТЕР была целиком пересмотрена работа с
кодовыми страницами. В предыдущих версиях существовала поддержка лишь
русскоязычных кодовых страниц (866, 1251, KOI8-R). В связи с распространением
СУБД ЛИНТЕР в том числе и в азиатском регионе, возникла необходимость работы с
символьными строками в японской, китайской, корейской и других кодовых
страницах. Хранение символьной информации в кодовых страницах, определяемых
пользователем, позволило также существенно ускорить работу СУБД в целом,
поскольку появилась возможность избежать трансляции данных из одних кодовых
страниц в другие. По умолчанию в систему включена поддержка следующих кодовых
страниц:
-
однобайтовые: 866, KOI8-R, 1251, 437, 1252, и с ISO 8859-1
по ISO 8859-16;
-
многобайтовые: 932 (Japanese Shift-JIS), 936 (Simplifield
Chinese GBK), 949 (Korean), 950 (Traditional Chinese Big5), EUC Japanese;
-
UNICODE и UTF8.
Реализация подсистемы
Для хранения информации о кодовых страницах на физическом
уровне было создано две служебные таблицы, входящие в системный словарь, которые
имеют следующую структуру:
-
$$$CHARSET – таблица, предназначенная для хранения кодовых
страниц. Поле IDENT содержит порядковый номер кодовой страницы, WIN_CODE – код
в ОС Windows, NAME – имя, PROP – информацию о свойствах кодовой страницы, PAGE
– номер страницы, в INFO собрана информация о «весе» символов кодовой
страницы, о верхнем/нижнем регистре и о преобразовании в UNICODE. Эта таблица
позволяет хранить как информацию об однобайтовых кодовых страницах, так и о
многобайтовых. Многобайтовые кодовые страницы хранятся в виде своих
составляющих – набора однобайтовых кодовых страниц и при загрузке в СУБД
«собираются» в единое целое с целью получения общей таблицы трансляции в/из
UNICODE.
-
$$$TRANSL – эта таблица предназначена для хранения
информации о трансляции однобайтовых кодовых страниц друг в друга. Поле IDENT
содержит порядковый номер трансляции, CSET_FROM – номер кодовой страницы, из
которой осуществляется трансляция, CSET_TO – номер кодовой страницы, в которую
осуществляется трансляция, NAM – имя трансляции, MAP – таблица трансляции,
собственно, и содержащая информацию о соответствии символов. Если нет готовой
таблицы трансляции, при необходимости преобразования символов из одной кодовой
страницы в другую она генерируется динамически – через таблицу
UNICODE-символов.
Следует отметить, что создание таблиц $$$CHARSET и $$$TRANSL
осуществляется на этапе создания системного словаря с помощью SQL-запросов.
Добавление и удаление записей в эти таблицы также осуществляется с помощью
команд SQL: «CREATE (DROP) CHARACTER SET …;» и «CREATE (DROP) TRANSLATION …;»
Настройка и работа
В только что созданной базе данных таблицы $$$CHARSET и
$$$TRANSL отсутствуют, и для работы базы данных используется интегрированная
кодовая страница 20127(US-ASCII), имеющая имя «DEFAULT» и содержащая 127
символов. После создания системного словаря эта кодовая страница может быть
подменена любой другой, носящей то же имя. Таким образом, кодовая страница «DEFAULT»
является первой кодовой страницей по умолчанию в базе данных. Кодовая страница
по умолчанию используется в двух случаях:
-
в символах этой кодовой страницы хранится системный словарь
(названия таблиц, столбцов, триггеров, процедур и т. д.);
-
при создании таблиц и столбцов без явного указания кодовой
страницы, им назначается кодовая страница базы данных по умолчанию.
В настоящее время кодовая страница по умолчанию может быть
только однобайтовой. Сменить кодовую страницу по умолчанию можно с помощью
SQL-команды «SET DATABASE NAMES …;». Например команда «SET DATABASE NAMES
CP866;» устанавливает по умолчанию кодовую страницу 866. Если вслед за этим
подать команду «CREATE TABLE A (B CHAR(5));», то для таблицы A и столбца B будет
установлена кодовая страница 866. Если же, например, подать команду «CREATE
TABLE A (B CHAR(5) CHARACTER SET CP1251);», то для столбца B будет установлена
кодовая страница 1251.
Для нормальной работы с кодовой страницей рекомендуется явно
задать ее на клиентской части. Это проще всего сделать, задав переменную
окружения:
set LINTER_CP=CP932
Этот пример для случая, если мы хотим работать с японской
SJIS-кодовой страницей CP932.
Данные в столбцах в произвольной национальной кодовой
странице могут храниться двумя способами:
В качестве длин текстовых полей указывается их размер в
байтах.
Проиллюстрируем оба этих способа на примере японской кодовой
страницы CP932 (эта японская кодовая страница содержит как однобайтовые, так и
двухбайтовые символы.):
CREATE TABLE TBL_JP( JSTR CHAR( 30 ) CHARACTER SET CP932 );
INSERT INTO TBL_JP VALUES ('日本語1');
INSERT INTO TBL_JP VALUES ('日本語2');
CREATE TABLE TBL_JP1( JSTR1 NCHAR( 30 ));
INSERT INTO TBL_JP1 VALUES (N'日本語1N');
INSERT INTO TBL_JP1 VALUES (N'日本語2N');
На рисунке 1 показано, как будет представлена выборка из
данной таблицы в утилите LinDesk:
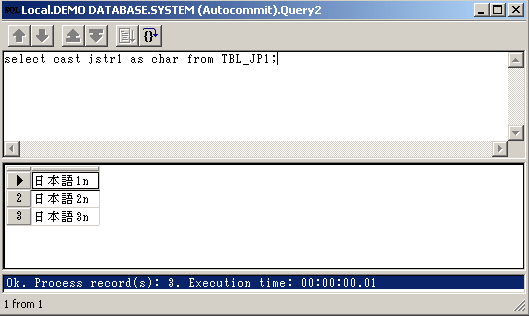
Рисунок 1. Отображение
национальных символов.
Следует отметить еще один важный момент. Поскольку хранение
многобайтовых кодовых страниц требует существенного объема оперативной памяти,
то внутри СУБД такие страницы хранятся в отдельной очереди, которая по умолчанию
не инициализирована. Ее инициализация происходит только в результате занесения в
таблицу $$$CHARSET первой многобайтовой кодовой страницы и последующего
перезапуска базы данных.
В заключение следует сказать, что реализованная в шестой
версии СУБД ЛИНТЕР система многоязыковой поддержки обладает рядом существенных
положительных качеств: простота реализации, возможность гибкой настройки,
расширяемость данной системы по мере необходимости. В то же время следует
обратить внимание, что для полноценного использования всех этих возможностей
следует очень серьезно подойти к проектированию базы данных, а также внимательно
изучить примеры, прилагаемые к документации СУБД.
Многие современные поисковые системы (например, электронные
магазины, информационные порталы и т.п.) предъявляют очень высокие требования к
скорости отработки поисковых запросов при условии одновременной работы большого
количества клиентов. Кроме того, развиваясь, такие системы должны легко
масштабироваться без ущерба для скоростных характеристик системы.
Один из способов удовлетворения этой потребности – реализация
в СУБД механизма асинхронной репликации. Основная идея репликации заключается в
том, что вместо одной базы данных, с которой должны работать все клиенты,
создается несколько одинаковых (по крайней мере, частично) баз данных на разных
машинах. Клиенты имеют доступ к некоторому распределяющему устройству
(реализованному аппаратно или каким-либо программным методом), которое при
появлении нового клиента оценивает загрузку каждого сервера и направляет клиента
на наименее загруженный, с которым он (клиент) и будет работать до отсоединения.
Серверы баз данных связаны между собой, и все сделанные
изменения пересылают друг другу с тем, чтобы привести реплицируемые объекты
(таблицы базы данных) в полное соответствие. Поскольку репликация асинхронная,
этот процесс происходит не сразу, а в течение некоторого времени. В этот период
данные на разных серверах будут отличаться.
Такое построение позволяет значительно (в идеальном случае,
прямо пропорционально количеству серверов) увеличить производительность системы
и наращивать её по мере роста нагрузки (увеличения количества клиентов или
размеров базы данных) простым прибавлением серверов в систему репликации.
Для управления системой на логическом уровне в СУБД ЛИНТЕР
используются правила репликации, которые создаются обычным SQL-запросом и
представляют собой описание того, какие объекты, куда и каким образом
реплицировать. В ЛИНТЕР создание правила репликации выглядит так:
CREATE REPLICATION RULE имя_правила
FOR [ имя_пользователя. ] имя_таблицы
[ TO имя_удаленной_таблицы ]
ON NODE имя_сервера
[ USER имя_пользователя ] [ PASSWORD 'пароль' ]
[ ENABLE / DISABLE ]
[ SYNC / ASYNC ]
[ IGNORE OLD VALUE / CHECK OLD VALUE / CORRECT NUMBERS ];
Сама репликация происходит по первичным ключам – каждая
таблица, подлежащая репликации должна содержать первичный ключ, значение
которого используется для идентификации (при удалении и изменении значений) в
реплицируемых таблицах.
Есть три модели поведения системы при возникновении
рассогласования между значениями записей в базах данных реплицируемых серверов.
Если такая ситуация возникла во время выполнения операции (update, delete),
можно предпринять следующие действия:
-
IGNORE OLD VALUE – игнорировать несовпадение старого
значения
-
CHECK OLD VALUE – обязательно проверить старое состояние и
вернуть ошибку, если нет полного совпадения.
-
CORRECT NUMBERS – если не совпадают числовые значения,
сохранить разницу между старым и новым значением.
Неразрешимые коллизии могут возникнуть при одновременной
вставке во взаимно реплицируемые таблицы одинакового значения первичного ключа.
В системе асинхронной репликации участвуют два или более
серверов, на каждом из которых работает ЛИНТЕР и два процесса репликации,
In и Out (они представляют собой отдельные потоки в
NT или процессы в UNIX). Объектами репликации являются таблицы базы данных,
список которых вместе с правилами и адресами рассылки хранится в БД.
Сервер репликации (СР) представляет собой специальный
процесс, который получает данные об измененных данных от СУБД ЛИНТЕР и сохраняет
эти данные в очередях репликации в хранилище данных репликации (ХДР),
которое представляет собой соответствующим образом «урезанное» ядро. Оно же
будет использоваться процессами In и Out для
получения данных, подлежащих репликации и рассылке.
Функции компонентов:
– основное ядро, работает независимо
от остальных компонентов. Должно обеспечивать только одну дополнительную
функцию: выдавать для СР измененные записи.
Сервер репликации
– запускается отдельно и
независимо от СУБД, он в свою очередь запускает ХДР, In и Out; формирует
структуру данных в ХДР, запрашивает и получает данные от ЛИНТЕР, сохраняет их
в ХДР, формирует очередь рассылки в ХДР.
Хранилище данных репликации
– это ЛИНТЕР, который
хранит данные для рассылки. К этим данным имеют доступ СР, процессы In, Out и
мониторы.
Процесс In
– получает от удаленного Out информацию
об измененных записях, после получения информации о подтверждении транзакции
выполняет транзакцию, отсылая код возврата отправителю. Получаемые данные
хранятся в ХДР в виде приемной очереди.
Процесс Out
– ожидает завершения транзакций
(хранящихся в ХДР) и рассылает данные по назначению. Получает и заносит в ХДР
коды возврата от удаленных серверов.
Элемент очереди рассылки включает в себя полную информацию о
старом и новом состояниях записи, адрес назначения, номер канала, производящего
операцию, номер транзакции и время операции. Эта информация заносится в таблицу
очереди рассылки на сервере репликации. В качестве первичного ключа этой таблицы
используется время операции.
Процесс In получает данные и помещает их в приемную
очередь, структура которой похожа на структуру таблицы очереди рассылки. После
этого он формирует ответ, уведомляющий отправителя о нормальном приеме.
Одновременно (возможно, с контролем над загруженностью ЛИНТЕР) происходит
собственно репликация, коды завершения сохраняются в таблице приемной очереди.
В качестве идентификатора кортежа используется первичный ключ
(для очереди рассылки это OPER_DATE (дата операции, она уникальна), на приемной
очереди это уже не первичный ключ, там идентификация происходит по OPER_DATE и
SERVER_SRC (передающий сервер)), описание которого передается от Out к In и
сохраняется в таблицах сервера репликации.
Если один из процессов (ЛИНТЕР или СР) завершается
некорректно, этот процесс стартует заново, восстанавливается и работа
продолжается. Повторное прохождение одного и того же блока отслеживается с
помощью времени операции (OPER_DATE).
В качестве протоколов проделанной работы используются эти же
очереди с соответствующими кодами завершения и создаваемый компонентами
log-файл.
При необходимости администратор системы может запустить
процедуру очистки очередей сервера репликации, при этом будут удалены все уже
реплицированные записи, возможно, до указанной администратором даты.
Как уже было замечено, асинхронная репликация может
использоваться в системах, которые предусматривают большое количество поисковых
запросов при относительно незначительных изменениях. Это не значит, что нельзя
делать массированных изменений БД, однако эффективность репликации высоко
динамичных баз данных оказывается невысокой и, как правило, не соответствует
поставленным задачам.
Кроме того, важной особенностью системы является возможность
временного рассогласования данных на разных серверах в том случае, если клиенты
производят изменения.
Итак, к достоинствам систем асинхронной репликации следует
отнести:
-
Хорошую масштабируемость (стремящуюся к прямо
пропорциональной зависимости от количества серверов, участвующих в процессе
репликации в случае отсутствия изменяющих запросов)
-
Высокую скорость выполнения запросов: в идеальном случае,
если количество одновременно работающих клиентов равно или меньше, чем
серверов в системе репликации – достигается предельное значение
быстродействия: один клиент – один компьютер.
-
Хорошая отказоустойчивость: отказ одного или нескольких
серверов не приведет к остановке всей системы, а лишь немного замедлит работу,
так как клиенты временно будут перераспределены между оставшимися серверами.
Отказавший сервер может быть запущен в любой момент и сам произведет все
необходимые действия для синхронизации с остальными.
Недостатки:
-
Падение эффективности в случае высокой динамики изменений –
рассылка и параллельные изменения всех БД снижают скорость отработки поисковых
запросов.
-
Временное рассогласование данных на серверах, которое
практически исключает применение систем асинхронной репликации в приложениях,
требующих абсолютной синхронности данных, получаемых разными клиентами.
-
Необходимость нетривиального администрирования, разрешение
коллизий с одинаковыми первичными ключами или по какой-либо причине
рассогласованными данными. Уменьшить вероятность неразрешимых коллизий (или
даже исключить ее) можно на этапе проектирования приложения или, в ряде
случаев, при создании самих баз данных на разных серверах (например,
выделением для автоинкрементальных полей отдельных непересекающихся для
каждого сервера диапазонов значений).
Анализируя недостатки механизма асинхронной репликации можно
предложить несколько усовершенствований, которые могли бы увеличить
эффективность работы системы (большинство из них в настоящее время находятся на
стадии реализации и войдут в следующие версии системы):
-
Падение производительности во время проведения изменений
подсказывает, что репликацию данных следует производить не во время их
поступления, а в момент наименьшей загрузки. Это может быть определенное время
суток (ночь, например) или действительно момент небольшой загрузки,
определяемый сервером репликации. Конечно, такой подход увеличивает время, в
течение которого данные на серверах будут рассогласованы, так что этот вопрос
остается «на совести» администратора системы или проектировщика приложения.
-
Сложность администрирования является стимулом для написания
программы-администратора, которая может взять на себя ряд основных и наиболее
часто требующихся функций: чистка хранилища (в зависимости от накопившихся
данных или по времени), отслеживание коллизий, проверка и синхронизация
реплицируемых таблиц и многое другое.
-
Возможно усложнение правил репликации, введение
горизонтальной (только выборочные записи) и вертикальной (выборочные столбцы)
репликации.
-
Рассылка произведенных изменений может быть синхронной (с
ожиданием ответа) и асинхронной – изменения рассылаются, а ответ когда придет
– тогда и придет. Второй способ быстрее, но не всегда гарантирует
последовательное выполнение транзакций (хотя принципиально этот вопрос
решаем).
Итак, после анализа достоинств и недостатков асинхронной
репликации можно сделать вывод, что в не очень динамичных приложениях система
асинхронной репликации является практически оптимальным решением, которое не
предъявляет слишком больших требований к аппаратуре и, следовательно, выигрывает
и с точки зрения соотношения цена/производительность. Наиболее целесообразно
применять асинхронную репликацию в приложениях, которые предъявляют высокие
требования к производительности поисковых запросов и не критичны к временному
расхождению данных.
Система синхронизации RelXSync
RelXSync – это программное решение, предназначенное для
построения распределенных прикладных систем, работающих с реляционными базами
данных. Оно обеспечивает возможность off-line работы с информацией для удаленных
и мобильных клиентов, а также последующей двунаправленной синхронизации данных с
центральным сервером. Связь с базой данных осуществляется через ODBC, поэтому на
базе RelXSync можно строить решения для гетерогенных систем.
RelXSync содержит следующие основные компоненты: механизм
определения изменений, модуль формирования пакетов синхронизации, модуль
обработки пакетов синхронизации, транспортный уровень и модуль интеграции со
службой каталогов. RelXSync может быть запущен в режиме клиента (та сторона,
которая инициирует процесс синхронизации баз данных) и в режиме сервера (та
сторона, которая ожидает начала процесса синхронизации данных).
Структура RelXSync показана на рисунке 2.
При установке RelXSync в базе данных создается набор таблиц с
метаданными синхронизации. В метаданных хранятся списки узлов синхронизации
(удаленных баз данных), списки таблиц, которые необходимо синхронизировать,
правила синхронизации и т.д. Кроме того, для прикладных таблиц, которые включены
в процесс синхронизации данных, создаются вспомогательные таблицы.
Вспомогательные таблицы используются механизмом определения изменений для
хранения служебной информации. Механизм определения изменений базируется на
триггерах. Когда прикладная задача модифицирует данные, информация об этом
событии заносится во вспомогательные таблицы. При этом объем служебной
информации ограничен и не увеличивается при многократных изменениях одной и той
же записи. Синхронизация локальной базы с удаленным узлом возможна в режимах
on-line и off-line.

Рисунок 2.
В режиме on-line клиент синхронизации устанавливает
соединение с сервером синхронизации по одному из поддерживаемых on-line
протоколов (TCP/IP, HTTP и т.д.). Затем формируется пакет синхронизации,
передается на удаленный сервер БД и там обрабатывается. В зависимости от
обстоятельств пакет синхронизации может содержать либо все данные (начальная
синхронизация, восстановление после сбоев), либо данные, которые были
модифицированы с момента последнего сеанса синхронизации с данным узлом. Модуль
интеграции со службой каталогов определяет, какие именно таблицы и по каким
условиям будут выгружены в удаленную базу. После успешной обработки пакета
удаленной стороной в локальную базу возвращаются изменения, которые произошли в
удаленной базе. На этом сеанс синхронизации завершается. В случае off-line
протокола алгоритм обмена пакетами зависит от настроек RelXSync.
RelXSync обеспечивает возможности обмена данными между
синхронизируемыми базами данных при помощи следующих сетевых протоколов:
-
TCP/IP – наиболее быстрое и надежное решение. Обеспечивает
дуплексную сессию синхронизации. При необходимости шифрации сообщений имеется
возможность работать через SSL.
-
HTTP – аналогично TCP/IP обеспечивает получение
подтверждений о приходе пакетов от базы-приемника, и сохранения пакетов не
требуется. Серверная часть (принимающая соединения) реализована в варианте
собственного сервера, понимающего подмножество http. Главным преимуществом при
использовании этого протокола является возможность работы через Internet.
-
E-MAIL – Данный вариант обмена не гарантирует надежной
доставки данных, но позволяет использовать любые возможности для отправки
данных, т.к. e-mail является очень распространенным сервисом.
-
FILE – Имеет такие же ограничения, как и E-MAIL. Пакет
синхронизации данных оформляется в виде файла. Доставка файла осуществляется
по ftp, с помощью гибких носителей и т.п.
В качестве прочих достоинств RelXSync следует отметить:
Драйверы и интерфейсы
Наличие драйвера ODBC, стандартного интерфейса SQL CLI –
норма для любой уважающей себя СУБД. ЛИНТЕР – не исключение. Стоит отметить, что
драйвер ODBC (3.х) СУБД ЛИНТЕР существует для всех платформ, а не только для
Microsoft Windows, и по сути своей является ещё одним универсальным API для
разработки приложений. Это очень важный момент, обеспечивающий приложениям
дополнительный уровень переносимости. Специально для версий ЛИНТЕР 6.x, в
которых реализована поддержка национальных (да и вообще любых) кодировок,
существует UNICODE ODBC-драйвер. Реализована полная поддержка ODBC
esc-последовательностей. Для сокращения размеров приложений, рассчитанных на
встроенные системы, возможно использование библиотеки с урезанной
функциональностью.
Большинство современных приложений разрабатывается с
использованием объектно-ориентированных языков программирования. При работе на
платформах Microsoft провайдер OLE DB СУБД ЛИНТЕР облегчит разработку программ в
различных средах программирования, использующих компоненты ADO, например, в
среде Visual Basic.
Рисунок 3. Список таблиц в Браузере объектов
(Linux).
Специально для поклонников Delphi и стремительно набирающего
обороты Kylix, в ЛИНТЕР разрабатывается интерфейс DBExpress. При разработке
приложений на Delphi можно, конечно, использовать и ADO, однако для Kylix такой
возможности нет, и наличие "родных" компонентов DBExpress – практически
единственный вариант обеспечить совместимость.
Очень популярен у разработчиков web-приложений скриптовый
язык PHP. Фактически с момента появления этого языка появилась возможности
обращения из него к ЛИНТЕР. С развитием PHP разработчики этого популярного
средства реализовали набор вызовов для работы с базами данных через ODBC. Однако
этот шлюз не поддерживает большую часть функциональных возможностей этого
интерфейса, например, работу с массивами параметров и ответов. Поэтому для СУБД
ЛИНТЕР была сделана собственная реализация шлюза PHP->ODBC, которая позволяет
при работе с PHP использовать практически все возможности ODBC.
Администратор СУБД ЛИНТЕР 6.х
До появления данной утилиты, администрирование СУБД ЛИНТЕР на
разных платформах осуществлялось в утилитах с псевдографическим интерфейсом или
из командной строки утилиты inl. Только в Win32 был практически полноценный
набор утилит администрирования, состоящий из Администратора ЛИНТЕР и Рабочего
Стола ЛИНТЕР (LinDesk).
Вполне естественно, что разный стиль интерфейсов в различных
ОС вызывал существенные нарекания как разработчиков, так и пользователей
гетерогенных систем на основе СУБД ЛИНТЕР. Заменить подобный "зоопарк" была
призвана новая межплатформная утилита с графическим интерфейсом пользователя –
Администратор 6.0. В идеале, данный проект должен интегрировать в себе функции
как Администратора, так и Рабочего Стола, и выглядеть одинаково в разных ОС.
Функциональность утилиты
Утилита администрирования СУБД ЛИНТЕР представляет собой
многооконное графическое приложение, выполняющее следующие функции:
-
Работа с таблицами данных – создание, редактирование
структуры таблиц, занесение данных, их модификация, наложение ограничений
ссылочной целостности (создание, удаление внешних ключей, ограничений
уникальности, индексов).
-
Обмен данными – экспорт данных из таблиц в файлы различных
форматов (текстовые, гипертекстовые, XML).
-
Создание, удаление, просмотр свойств представлений и
синонимов таблиц.
-
Работа с учетными записями пользователей: создание
пользователя, внесение его в группу доступа, назначение прав доступа к
таблицам данных, назначение расписания соединений с БД, просмотр отчета по
доступу к объектам БД, редактирование его свойств.
-
Работа со специфическими объектами БД, такими, как станции,
устройства, каналы. Разрешение и запрещение доступа к устройствам, станциям.
-
Создание и удаление ролей, уровней и групп доступа,
назначение ролей пользователям, включение их в группы доступа, управление
различными видами доступа к таблицам – мандатным и дискреционным.
-
Создание, редактирование и выполнение произвольных
SQL-запросов.
-
Создание SELECT-запросов с помощью визуальных инструментов.
Особенности утилиты
На данный момент Администратор функционирует в Windows NT,
LINUX, Free BSD и Sun Solaris, и на всех этих платформах предоставляет
пользователю единообразный интерфейс. В качестве примеров ниже приведены
скриншоты приложения из разных ОС. Для облегчения освоения инструмента многие
элементы сделаны в стиле Рабочего Стола Windows.
Список доступных серверов содержится в файле nodetab.
Приложение позволяет отображать объекты базы данных двумя
способами – в виде дерева и в виде списка. На рисунке 4 изображены наиболее
часто используемые окна приложения: вверху располагается Главная Панель, слева –
Инспектор БД, справа сверху вниз список таблиц, редактор данных таблицы и
редактор SQL-запросов.
Браузер объектов предназначен для отображения списка
однородных объектов и выполнения операций над ними.
Функции управления объектами зависят от типа отображаемых в браузере объектов.
Для создания, просмотра и изменения свойств объектов базы
данных предназначены различные диалоговые окна, например, окно просмотра
свойств таблицы (Рисунок 5).
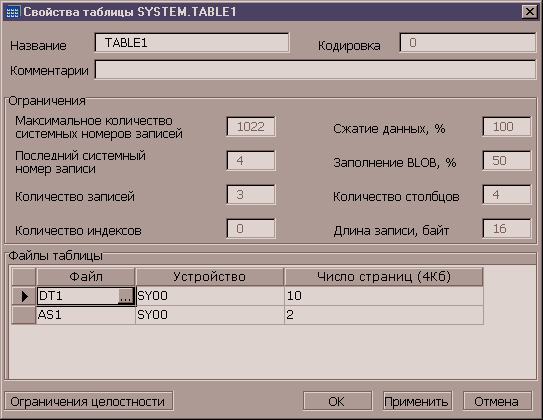
Рисунок 5. Диалог
свойств таблицы.
Расширенный редактор запросов. В новой версии ЛИНТЕР для
создания, редактирования и выполнения SQL-запросов используется Расширенный
редактор запросов (рисунок 6).
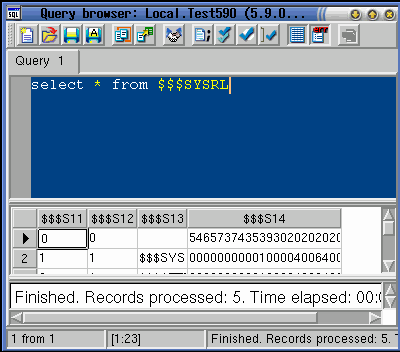
Рисунок 6. Расширенный
редактор запросов (Linux).
Ниже перечислены основные нововведения в Расширенном
редакторе запросов:
-
выделение типов лексем цветами, которые можно настроить в
диалоге опций;
-
экспорт результатов выборки в файл;
-
выбор соединения, под которым следует выполнить запрос.
Дизайнер запросов. Для облегчения построения
SELECT-запросов с большим количеством связей между таблицами в шестой версии
СУБД ЛИНТЕР предусмотрен Дизайнер запросов (Рисунок 8).
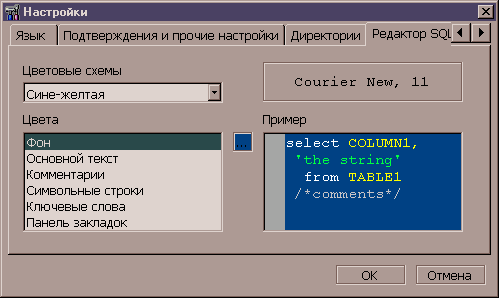
Рисунок 7. Диалог настроек приложения
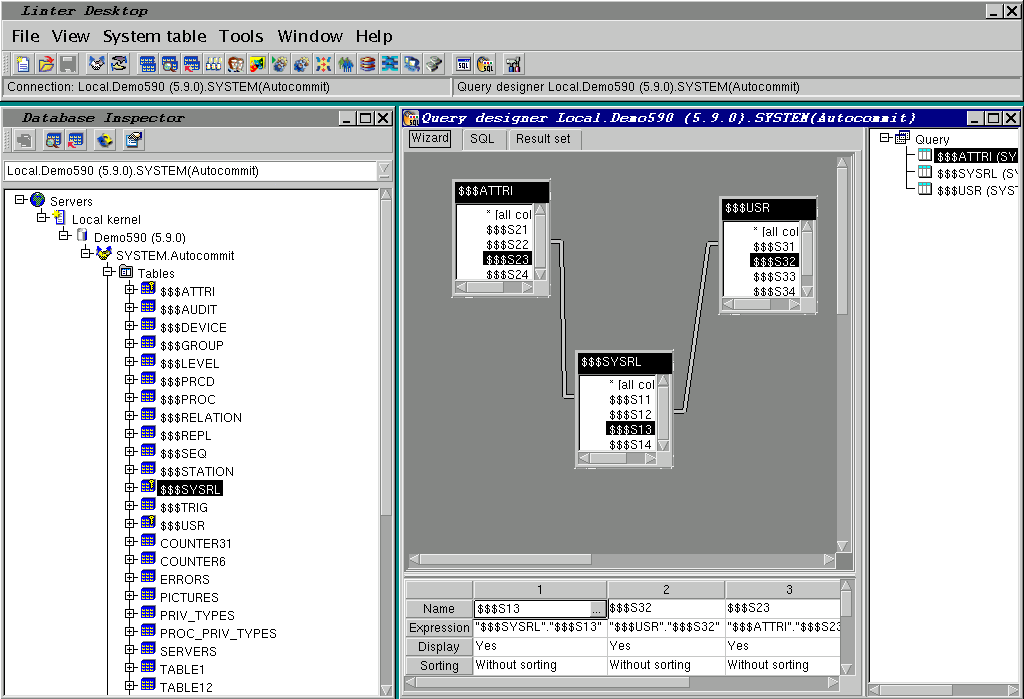
Рисунок 8. Визуальное
проектирование SQL-запроса (Sun Solaris).
Окно дизайнера запросов состоит из трех закладок и дерева,
отображающего уровни вложенности подзапросов. Закладки имеют различную
функциональность и называются Мастер, SQL запрос и Результат.
На закладке Мастер пользователь выбирает таблицы, задает связи между
ними, ограничения на значения столбцов. На закладке SQL-запрос
пользователь может просмотреть текст созданного запроса. На закладке
Результат можно просмотреть выборку – результат выполнения запроса.
Для удобства работы с Администратором предусмотрены различные
настройки приложения. Например, есть возможность настройки шрифтов в различных
группах элементов управления, языка приложения, подтверждения действий
пользователя, директории вызываемых утилит, раскраска SQL-редактора.
На данный момент в Администраторе реализованы практически все
функции по работе с объектами базы данных. В ближайшем будущем в дополнение к
уже существующим планируется реализовать такие функции, как добавление и
удаление серверов, запуск и остановка ядра, создание и удаление базы данных на
удаленном сервере.
Также планируется сборка и отладка проекта в других
UNIX-подобных операционных системах.
Утилита резервного копирования БД – LHBX
Эта программа предназначена для резервного сохранения
информации из базы данных СУБД ЛИНТЕР в файл архива и, при необходимости,
последующего восстановления базы данных. Данные возможности обеспечиваются для
всех программных платформ, на которых функционирует СУБД ЛИНТЕР.
Функциональность утилиты
Утилита представляет собой многооконное графическое
приложение, выполняющее следующие функции:
-
Полное сохранение базы данных в файл архива;
-
Пообъектное сохранение базы данных в файл архива;
-
Пообъектное восстановление базы данных из файла архива;
-
Выполнение всех предыдущих функций с использованием
Мастеров.
Особенности утилиты
Утилита на данный момент функционирует в Windows NT, LINUX,
Free BSD, Sun Solaris и предоставляет пользователю единообразный, интуитивно
понятный интерфейс. Работать можно с узлами, описанными в файле nodetab,
а также с локальным ядром.
Утилита тестирования БД – TESTDBX
Программа предназначена для полного тестирования и
восстановления базы данных СУБД ЛИНТЕР. Ниже приводится краткое описание
интерфейса программы и возможностей, которые она предоставляет.
Функциональность утилиты
Утилита представляет собой многооконное графическое
приложение, выполняющее следующие функции:
-
Тестирование всей базы данных;
-
Тестирование выделенного списка таблиц;
-
Восстановление поврежденных таблиц;
Особенности утилиты
Утилита TESTDBX на данный момент функционирует в Windows NT,
LINUX, Free BSD, Sun Solaris. Для работы утилиты необходимо указать путь к базе
данных, которую следует тестировать (восстанавливать), поэтому можно сказать,
что при запуске TESTDBX проводится тестирование локальной базы данных.
Утилита перемещения данных – MIGRATION
Программа предназначена для:
-
Импорта данных в СУБД ЛИНТЕР
-
Экспорта данных;
-
Экспорта структуры объектов базы данных;
-
Перемещения базы данных в рамках одной платформы;
-
Перемещения базы данных между различными платформами;
-
Перемещения базы данных между различными версиями СУБД
ЛИНТЕР;
-
Создания новой базы данных.
Ниже приводится краткое описание интерфейса программы и
возможностей, которые она предоставляет.
Мастер перемещения данных
Мастер перемещения данных предоставляет пользователю простой
и наглядный способ перемещения существующей базы данных в новую. Мастер состоит
из нескольких последовательных шагов, служащих для установки тех или иных
параметров, необходимых для перемещения данных.
Работу Мастера можно разделить на несколько логических
этапов:
-
Этап полного сохранения (экспорта) базы данных;
-
Этап создания новой базы данных и установления связи с ней;
-
Этап создания структуры (объектов) в базе данных и импорта
данных в таблицы.
Каждый из этапов можно пропустить и перейти непосредственно к
необходимому этапу (например, можно пропустить этап сохранения, т.к. файлы
экспорта уже были созданы на другой платформе или были скопированы).
Рассмотрим работу мастера на реальном примере: необходимо
перенести демонстрационную базу данных во вновь созданную БД на той же локальной
машине.
Шаг первый – выбор метода сохранения (рисунок 9).
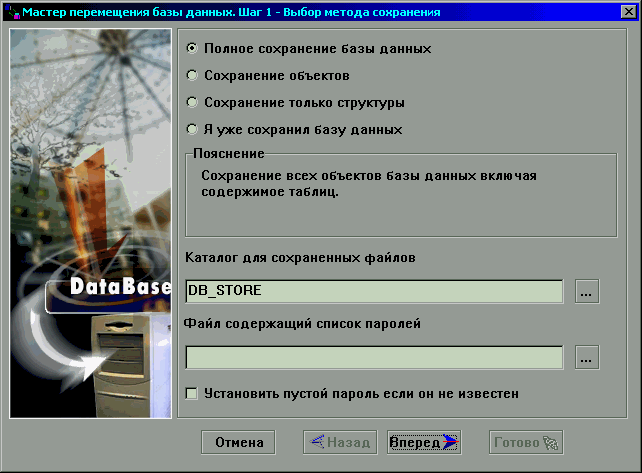
Рисунок 9. Перемещение
данных. Шаг 1.
Если выбрать сохранение объектов, то следующим шагом будет
необходимо выбрать объекты для сохранения (рисунок 10).
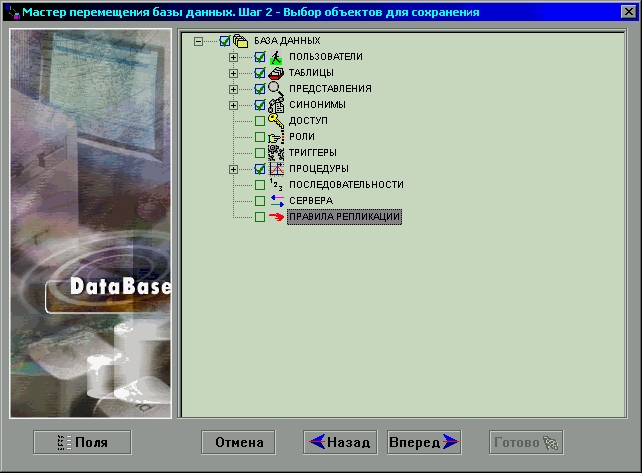
Рисунок 10.
Перемещение данных. Шаг 2.
Если оставить выбранными все объекты и нажать кнопку
Вперед, программа закроет окно мастера и выведет окно вывода результатов
(рисунок 11).
Если для сохранения были выбраны данные из таблиц других
пользователей, придется ввести пароль этого пользователя в открывшемся
диалоговом окне.
После того, как все объекты базы данных будут сохранены,
можно просмотреть log-файл, нажав кнопку Отчет. После нажатия на кнопку
Закрыть будет открыт следующий шаг мастера (рисунок 12).
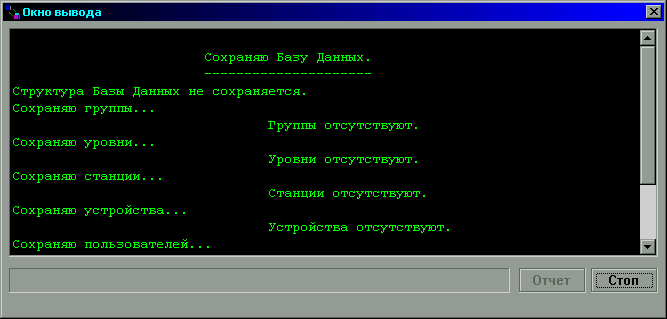
Рисунок 11. Перемещение данных.
Результаты сохранения.
На этом этапе будет произведено создание системных таблиц и
создание структуры базы данных, а также будут загружены данные в таблицы.
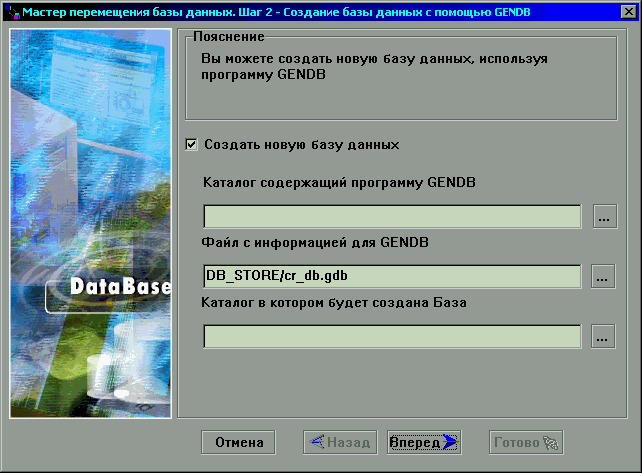
Рисунок 12.
Перемещение данных. Шаг 3.
На данном шаге можно создать новую базу данных, используя
программу gendb. Этот шаг можно пропустить, если убрать галочку с опции
Создать новую базу данных.
После создания базы данных будет открыт следующий шаг, на
котором необходимо запустить ядро СУБД ЛИНТЕР для вновь созданной базы данных и
установить соединение с запущенной базой данных (Рисунок 13).
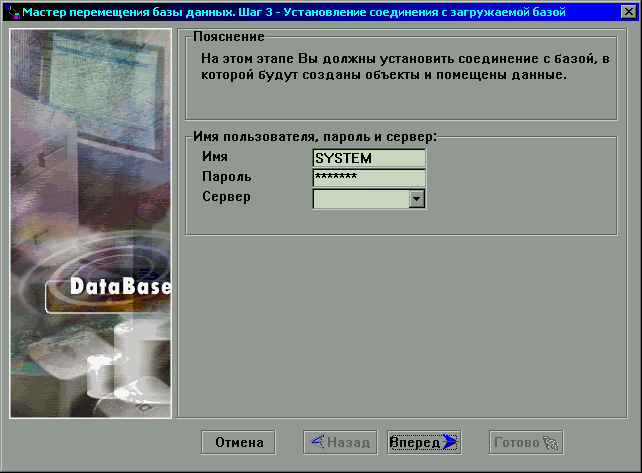
Рисунок 13.
Перемещение данных. Шаг 4.
После успешного установления соединения с базой будет открыт
последний шаг мастера перемещения данных (Рисунок 14).
Создание системных таблиц можно отключить, но делать это
очень не рекомендуется, так как база только что была создана и не содержит
необходимых системных таблиц, а, например, процедуры и триггеры без системных
таблиц восстановлены быть не могут.
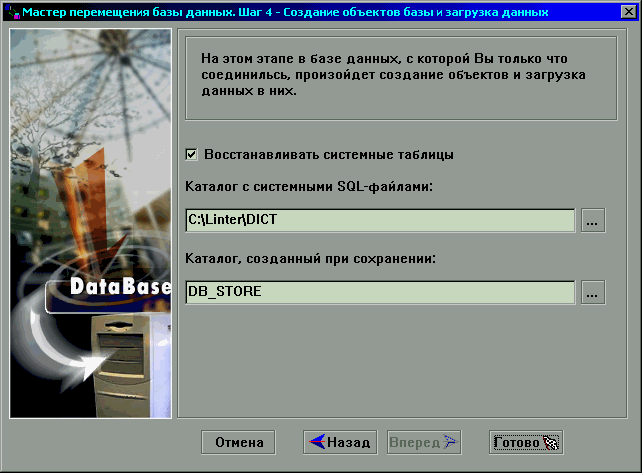
Рисунок 14.
Перемещение данных. Шаг 5.
После нажатия на кнопку Готово начнется процесс
создания объектов базы данных и загрузки таблиц (Рисунок 15).
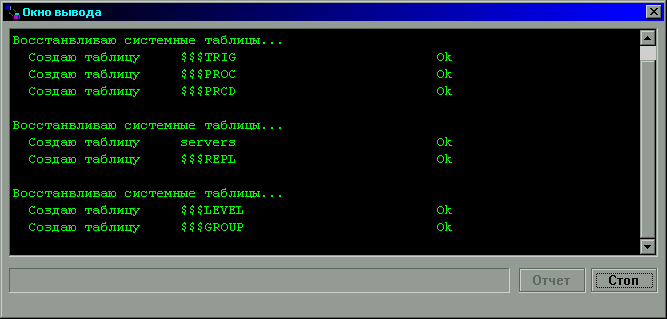
Рисунок 15.
Перемещение данных. Создание таблиц.
После создания системных таблиц и пользователей программа
приступит к созданию пользовательских таблиц и к загрузке данных в эти таблицы.
После этого будут созданы все остальные объекты.
По завершению работы программы база данных будет полностью
готова к работе.
Заключение
Мы рассмотрели некоторые возможности новой версии российского
SQL-сервера ЛИНТЕР. Безусловно, системы такого класса очень сложны и
многофункциональны. В рамках журнальной статьи просто невозможно дать полное
представление о СУБД. Мы постарались осветить только основные новшества,
реализованные в шестой версии Линтер. Однако и такого беглого обзора достаточно,
чтобы сказать, что эта СУБД стала еще более серьезным продуктом. Нововведения
ЛИНТЕР конечно, станут веским аргументом при выборе СУБД для новой разработки.
Copyright © 1994-2016 ООО "К-Пресс"