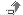|
���������� ������-������ 2009'3
|
|
|
DBA как детектив: выслеживаем блокировки
Опубликовано: 09.07.2010
Версия текста: 1.1
Если вас забавляет поиск и ликвидация проблем в SQL Server, то я скажу, не опасаясь возражений, что эта статья должна вас повеселить.
Я всегда себя чувствую лучше в конце дня, если смог найти источник проблемы и предложить ее решение. Быть SQL Server DBA, надзирающим за терабайтами критически важных данных, с одной стороны, довольно почетно, а с другой – грозит стрессом. Пугающе? Да, как в фильме ужасов, подозрительный код готов кинуться на вас из каждой тени. Приносит ли это удовлетворение? Конечно, если вы обнаруживаете, что вы на расстоянии одной временной таблицы или субзапроса от того, чтобы стать героем дня. Или героиней.
Эта статья целиком посвящена слежке за SQL Server и снятию слоя данных за слоем, пока не покажется голый металл проблемы. Это может быть одновременно забавной и кропотливой работой. Слова типа «мертвая точка» (дословный перевод слова deadlock, взаимоблокировки – прим.пер.) и «жертва» здесь общеприняты, так что пробираться по этому сумрачному миру нужно с опаской. А если все сложится плохо, что-то придется «убить». Эти бандитские повадки DBA заставляют многих, очень многих программистов сторониться нас. Они осторожно подкрадываются к нашим кубиклам и обращаются к нам с фальшивой почтительностью; «Не могли бы вы меня убить?» - спрашивают они с надеждой.
«Разумеется», - отвечаем мы.
Системные таблицы vs. DMV
Прежде чем начать поиск проблем, хотелось бы заметить, что шаги, выполняемые мной в роли DBA, позволяют работать с разными версиями SQL Server: 2000, 2005 и 2008. Я высоко ценю удобство Dynamic Management Views (DMV) в SQL 2005 и 2008, но в реальном мире существует много компаний, которые по-прежнему используют SQL Server 2000. Мне и хотелось бы сказать, что все серверы, которыми я управляю, работают под SQL Server 2005, но это не так. Причин, по которым компании не торопятся с обновлением версий, можно назвать множество, но двумя основными из них остаются затраты и поддержка приложений сторонних разработчиков.
Как бы то ни было, системные таблицы, которые я здесь использую, через несколько лет устареют, как, впрочем, и я. По этой причине я очень рекомендую всем, работающим в основном с SQL Server 2005 и выше, использовать DMV. С небольшими изменениями представленные здесь запросы могут использовать DMV вместо системных таблиц или системных хранимых процедур.
Дополнительную информацию по отображению Distributed Management Views на системные таблицы в SQL Server 2000, 2005 и 2008 можно найти в Books Online, "Mapping System Tables to System Views."
Выслеживание проблем с производительностью БД
Итак, вы администратор БД, и вы сидите в своем кубикле, или, если вам повезло в жизни, в своем угловом офисе с панорамным, слегка тонированным окном, выходящим на ручей с белками и гибискусом, слегка шелестит прекрасно настроенный кондиционер. ОК, скорее все же в кубикле... Раздается телефонный звонок. Звонят из техподдержки и просят посмотреть, что творится с приложением Z, поскольку пользователь Х позвонил и сказал, что в отделе Z все экраны белые и «замороженные», причем скорее всего вовсе не из-за хорошо работающего кондиционера...
Один из пользователей получил сообщение о таймауте из-за SQL, поэтому вам и позвонили. Я о вас ничего не знаю, но когда у вас в инфраструктуре более 100 приложений, связанных с SQL Server, вы не всегда помните, какая комбинация сервер/БД связывает фронтэнд с бэкэндом. Придется сперва спросить:
- «К какому SQL Server-у они подключаются?»
- «Не знаю точно, сейчас выясню», – отвечает техподдержка. Пауза. «Они понятия не имеют».
- «Ну хорошо, а как называется приложение?»
- «Это, хм, Accounts_Receivable_Generation1.4.»
- «Это сервер «G», – уверенно говорите вы. Какой-то DBA, задолго до вас, решил, что забавно будет назвать все серверы буквами алфавита, по одной на сервер. «G» в данном случае, конечно, интуитивное имя для сервера, где должно работать приложение A.P.G., потому что это приложение, получающее счета, а «G» означает «Gold», любимую онлайн-игрушку администратора. Сделав себе пометку переименовать сервер в ближайшие выходные, вы говорите техподдержке, что посмотрите, в чем проблема, и скажете им.
Дальше идет пример того, как я выслеживаю и решаю такие проблемы, часто неверно определяемые как проблемы «производительности БД».
Использование sp_who2
Первое средство диагностики в инструментарии каждого DBA – старая, проверенная хранимая процедура sp_who2. Есть еще Activity Monitor, который также весьма удобен, но я нашел в нем две неправильных вещи. Во-первых, если сервер перегружен блокировками или временными таблицами, Activity Monitor часто не удается запустить, и вы получаете сообщение об ошибке. Во-вторых, Activity Monitor for SQL Server 2008 радикально другой, и, на мой взгляд, он слишком сложен, чтобы использовать его при попытках как можно быстрее локализовать проблему. Это основная причина, по которой я вынужден использовать и 2005, и 2008 версии клиентских средств одновременно.
Sp_who2, с другой стороны, работает всегда и выдает результаты мгновенно. Она показывает, среди прочего, все блокировки на том экземпляре SQL Server, где имеются проблемы. Запуск sp_who2 на проблемном сервере показывает, что там действительно есть заблокированные процессы, как следует из поля BlkBy в результатах процедуры, см. Рисунок 1.
Я могу с первого взгляда определить, что SPID 55 заблокирован SPID 51, а SPID 54 заблокирован 55. Я также могу увидеть, что блокирующий SPID относится к БД DBA_Rep, до это та самая БД, которую использует выдуманное приложение A.R.G.
С помощью sp_who2 я нашел блокирующий процесс, причем он блокирует уже некоторое время. Пользователи злобствуют, скоро страсти накалятся, и в мой кубикл заявится три или четыре человека, которым во все остальное время нет никакого дела до инфраструктуры SQL Server-а. Они будут следить за всеми моими действиями в ожидании решения проблемы.
Рисунок 1. Блокированные запросы, обнаруженные sp_who2.
Для этого мне нужно быстро найти ответы на следующие вопросы:
- Кто и откуда исполняет запрос?
- Что делает запрос?
- Можно ли убить проблемный запрос?
- Если я убью запрос, откатится ли он успешно и освободит ли это заблокированные процессы?
Кто исполняет запрос?
Выяснить, кто и откуда исполняет запрос, обычно нетрудно, и, на самом деле, это видно из результатов sp_who2. В данном случае рисунок 1 говорит мне, что запрос исполняет sa из Microsoft SQL Server Management Studio, с локального сервера “G”.
Но в реальной жизни на вопрос «кто» не всегда так уж просто ответить. Некоторые приложения используют общий логин, абстрагируясь от пользователя. Пользователь может иметь корректную учетную запись, но эта запись не используется для прямого подключения к БД. Вместо этого учетная запись контролируется приложением, и обычно сохраняется в таблице в БД приложения. В таких случаях часто можно встретить общий логин приложения вместо пользовательского логина.
Вы можете также обнаружить, что запрос исходит от приложения, находящегося на другом сервере, возможно, Web-сервере. При этом поле ProgramName в результатах sp_who2 будет содержать что-либо типа ".Net Client". Это вам даст немного. Вы может также увидеть имя Web-сервера, но, опять же, это не много дает. Иногда вам может повезти, и вы увидите неожиданное приложение, например, Management Studio, Query Analyzer, Microsoft Access или еще какое-то, которое не должно напрямую, вне клиентского приложения, подключаться к рабочим данным. В этом случае прогресс налицо, и можно идти дальше, с уверенностью, что имя пользователя, программа и место известны. Если же вы ничего не можете вынести из этих результатов, это не страшно; вы все еще можете найти ответ на следующий по важности вопрос: что запрос делает?
DBCC: что запрос делает?
Microsoft был достаточно добр, чтобы снабдить нас множеством средств для диагностики таких проблем. Одно из таких средств – набор команд DBCC. DBCC, которое вы, как SQL Server DBA, прекрасно знаете, можно использовать для ряда важных задач, от проверки и починки испорченных БД ( DBCC CHECKDB), которые я описал в книге 'The DBAs Tackle Box', до выяснения, как ваш экземпляр SQL Server использует память (DBCC MEMORYSTATUS). Еще одна DBCC-команда, INPUTBUFFER, позволяет увидеть запрос, исполняемый конкретным SPID. Это очень полезно, нет, незаменимо для DBA-сыщика.
Использовать DBCC INPUTBUFFER, чтобы обнаружить «плохой запрос», блокирующий другой процесс, так же просто, как передать номер SPID, как показано на рисунке 2.
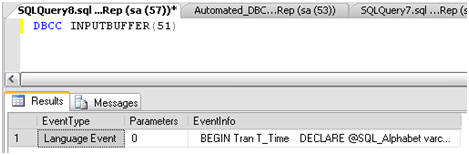
Рисунок 2. Результат DBCC INPUTBUFFER.
Как видите, в результате, возвращенном в табличном формате, отсутствует форматирование. Я могу расширить поле EventInfo, чтобы запрос выглядел лучше, но форматирования все равно не будет. Выдача результата в текстовом виде (для этого достаточно нажать кнопку "Results to Text" на инструментальной панели Management Studio) обычно дает лучший результат, как показано на рисунке 3.
Теперь видно, что кого-то посадили заполнять таблицу Important_Data (см. Листинг 1), и он ее будет заполнять, пока не заполнит всю.
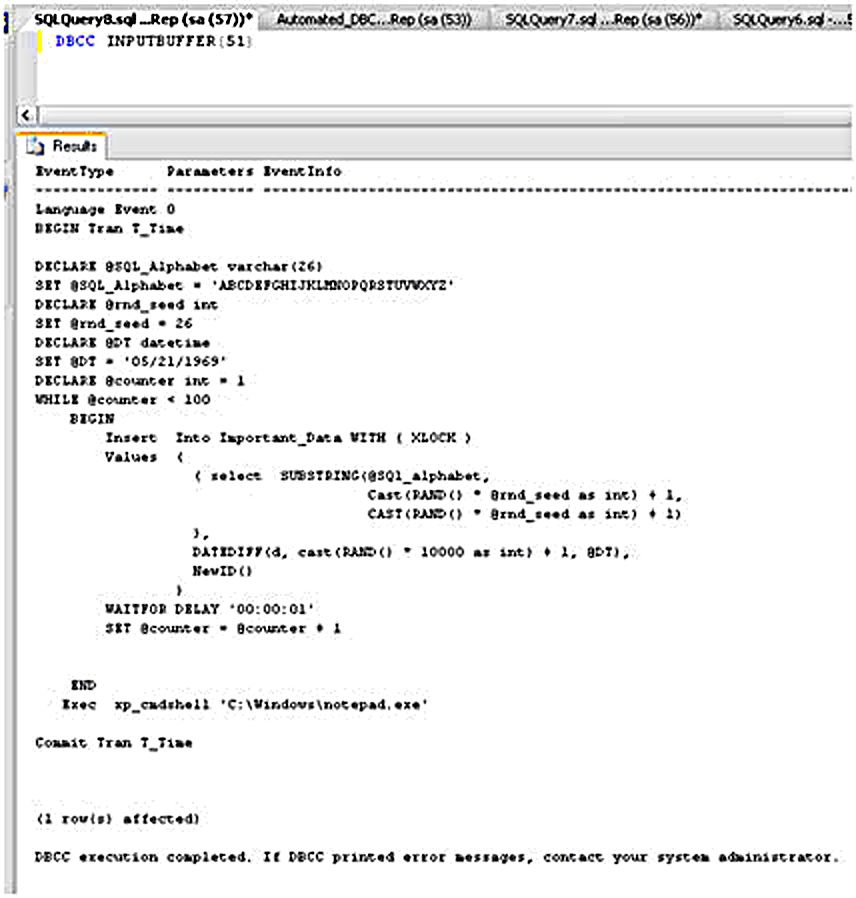
Рисунок 3. Вывод результата DBCC INPUTBUFFER в текстовом виде.
Листинг 1. Код создания таблицы Important_Data.
CREATE TABLE [dbo].[Important_Data](
[T_ID] [int] IDENTITY(1,1) NOT NULL,
[T_Desc] [nchar](40) NOT NULL,
[T_Back] [datetime] NULL,
[T_Square] [uniqueidentifier] NULL
) ON [PRIMARY]
GO
|
В листинге 2 во всей гнусной красе показан тот самый «Плохой Запрос»:
Листинг 2. Реально Плохой Запрос.
BEGIN Tran T_Time
DECLARE @SQL_Alphabet varchar(26)
SET @SQL_Alphabet = '
ABCDEFGHIJKLMNOPQRSTUVWXYZ'
DECLARE @rnd_seed int
SET @rnd_seed = 26
DECLARE @DT datetime
SET @DT = '05/21/1969'
DECLARE @counter int
SET @counter = 1
DECLARE @tempVal NCHAR(40)
WHILE @counter < 100
BEGIN
SET @tempVal = SUBSTRING(@SQl_alphabet,
Cast(RAND() * @rnd_seed as int) + 1, CAST(RAND() * @rnd_seed as int) + 1)
Insert Into Important_Data WITH ( XLOCK )
Values (
@tempVal,
DATEDIFF(d, cast(RAND() * 10000 as int) + 1, @DT),
NewID()
)
WAITFOR DELAY '00:00:01'
SET @counter = @counter + 1
END
Exec xp_cmdshell 'C:\Windows\notepad.exe'
Commit Tran T_Time
|
Если бы я встретил такой запрос на реальной системе, у меня сразу возникли бы подозрения насчет строки 15, а к строке 24 я бы слегка покраснел. На строке 29, где запрос вызывает xp_cmdshell и запускает Notepad.exe, мне потребовалось бы теплое одеяло и мягкий пол, куда бы я лег в позе эмбриона и несколько часов думал только о хороших вещах.
Конечно, здесь нужно сказать, что этот запрос – упражнение в нелепице; я его специально написал, чтобы создать блокировку и показать, как решаются такие задачи. «Плохой запрос» – это не работа разумного существа, но это не значит, чего-то подобного не может случиться на одном из ваших серверов (хотя вряд ли такое может случиться дважды). Обернутый в транзакцию T_Time, этот запрос вставляет по одной строки, 1000 раз подряд, в таблицу Important_Data, на основании случайных шаблонов для T_Desc и T_Back. Он делает это каждую 1 секунду. При этом он блокирует таблицу Important_Data, используя табличный хинт (XLock), так что никакой другой запрос не может обратиться к таблице Important_Data до его завершения, то есть пока не пройдет 1020 секунд, или 17 минут.
Наконец, у нас есть жуткий вызов xp_cmdshell. Многие, опять же, скажут, что такого в реальной жизни никто делать не станет. К сожалению, я точно знаю, что некоторые разработчики довольно широко используют xp_cmdshell. Иногда это является путем наименьшего сопротивления для запуска другого процесса, который должен вернуть значение вызывающему запросу. Но что если в один прекрасный момент ожидаемое значение не будет возвращено, а вместо него появится диалоговое окно, Ожидающее пользовательского ввода? Достаточно сказать, что это будет очень плохо, однако, я забегаю вперед. Все, что на текущий момент достаточно знать, что в нашем примере такой запрос «случился», и у меня нет нескольких часов на мягком полу, а теплое одеяло с моих плеч сорвал стоящий надо мной начальник. Так что лучше всего начать решать проблему.
Убийство проблемного запроса
На данный момент моя цель всего-навсего убить блокирующий SPID, чтобы начали проходить все стоящие за ним запросы. Так что убедившись, что бизнес не возражает против убийства проблемного SPID (поверьте, вы наверняка получите разрешение убить этот SPID), перехожу к довольно простому следующему шагу. Команда будет выглядеть примерно так:
Вот и все, правда? Если вы введете эту команду в SSMS, вы получите обычное обнадеживающее сообщение об успешном выполнении, как показано на рисунке 4.
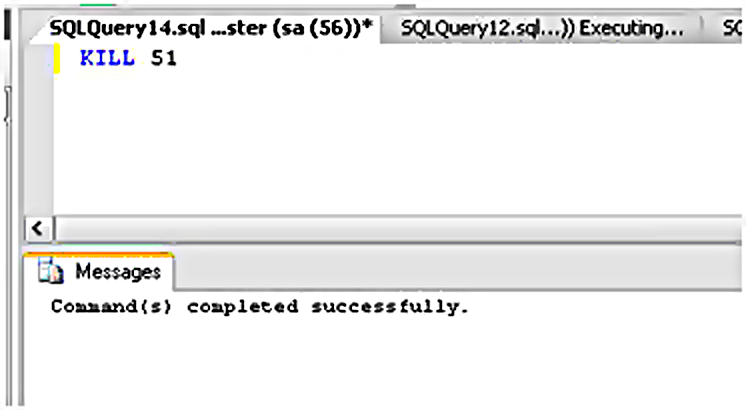
Рисунок 4. Убийство процесса Плохого Запроса (51).
Однако это сообщение может вводить в заблуждение. В некоторых случаях SPID действительно будет убит, но до отката проблемного выражения может пройти довольно много времени. У команды KILL есть опция, о которой я когда-то не знал – WITH STATUSONLY. После убийства SPID можно снова дать команду KILL с этой опцией и узнать, как долго, по подсчетам SQL Server, займет откат. Например, если вы 10 минут перестраивали индекс, а потом убили этот процесс, вы можете увидеть "% completion of rollback" с отсчетом до 100%.
В других случаях может оказаться, что несмотря на команду KILL, SPID не будет убит вовсе, и блокировка останется на своем месте. Если дать команду KILL WITH STATUSONLY для Плохого Запроса, вы увидите что-то похожее на рисунок 5.
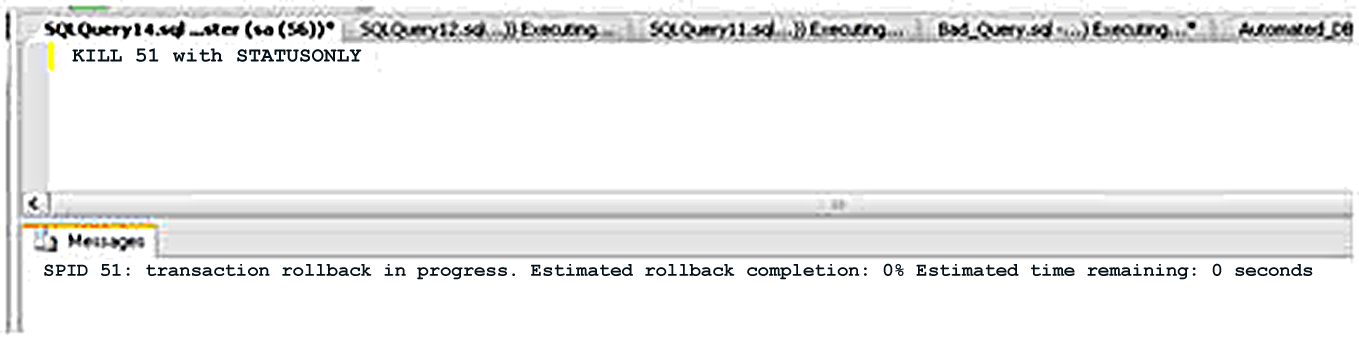
Рисунок 5. Неубиваемый SPID.
Как видите, SPID показывает, что выполнение расчетного отката – 0%, и время, требующееся на откат – 0 секунд, что указывает, что напрямую убить этот SPID не представляется возможным. Такая ситуация может возникнуть по причинам, о которых я говорил выше: блокирующий процесс запустил другой процесс, например, исполняемый файл, и SQL Server ожидает окончания того самого другого процесса. Единственный способ убить блокирующий SPID – перезапустить SQL Server или найти и убить тот процесс, завершения которого ожидает SQL Server.
В этом примере мне известно, что Плохой Запрос запустил Notepad.exe, так что у меня есть фора. На рисунке 6 показан скриншот Task Manager.
Рисунок 6. Notepad.exe не дает убить SPID 51.
Помните, что Notepad взят просто для примера; это может быть любой другой процесс, запущенный из xp_cmdshell и ожидающий пользовательского ввода для завершения.
Все, что мне нужно сделать – завершить процесс Notepad.exe, и блокировка будет снята, а ресурсы освобождены. Заметьте, что Notepad.exe запущен под учетной записью SYSTEM. Когда SQL Server дает команду ОС через xp_cmdshell, Notepad запускается как системный, а не пользовательский процесс. Щелчок правой кнопкой мыши и выбор "End Process" завершает работу Notepad, позволяя удалить SPID 51 и продолжить выполнение всех ранее заблокированных процессов.
Любые выражения INSERT, предшествовавшие Notepad в данной транзакции, следует считать отмененными.
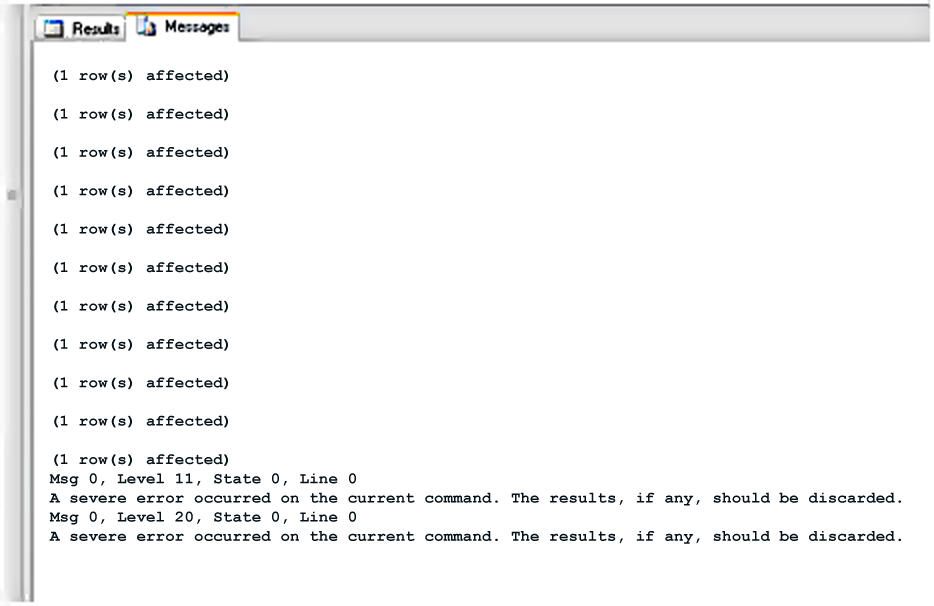
Рисунок 7. Отменяем все транзакции убитого SPID.
В этом можно убедиться с помощью короткого запроса к таблице Important_Data, показанного на рисунке 8, и подтверждающего, что после выражения KILL и завершения Notepad.exe никаких записей не осталось.
Использование sp_lock
Прежде чем показать запрос, автоматизирующий обнаружение проблемных запросов (здесь я опять забегаю вперед), хотелось бы поговорить о другой важной характеристике запросов с низкой производительностью, а именно, о безудержной трате ресурсов.
Очень важно отслеживать использование ресурсов CPU и I/O, подробно я собираюсь рассказать об этом в следующей статье, посвященной отслеживанию производительности и оповещениям. Здесь же я хочу сосредоточиться на блокировании ресурсов. Sp_who2 показывает хорошую картину процессов, которые могут блокировать другие процессы, и некоторое начальное представление об использовании ресурсов типа CPU и I/O, но не говорит ничего о различных блокировках, наложенных для исполнения процесса.
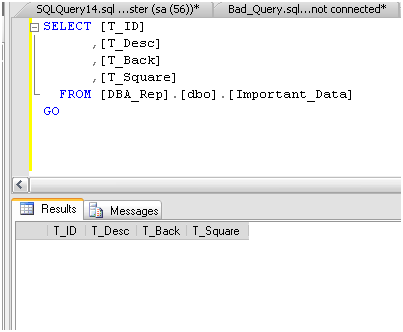
Рисунок 8. После KILL в Important_Data нет записей.
Блокировка – это «нормальное» действие SQL Server, то есть это механизм, посредством которого SQL Server управляет параллельным доступом к данному ресурсу нескольких конкурирующих процессов. Однако как DBA вы должны распознавать поведение блокировок, явно указывающее, что что-то не так.
Распространенные типы блокировок:
- RID – блокировка одной строки
- KEY – диапазон ключей в индексе
- PAG – блокировка страницы данных или индекса
- EXT – блокировка экстента
- TAB – блокировка таблицы
- DB – блокировка БД
В дополнение к типам блокировок, относящимся к ресурсам или объектам, у SQL Server есть общие режимы блокировок:
- S – Совмещаемая (или разделяемая, Shared) блокировка
- U – блокировка обновления (Update)
- X – монопольная (Exclusive) блокировка
- Intent-блокировки (IS, IU, IX) – используются для создания иерархии блокировок.
- BU – используется при массовой заливке данных в таблицу
- Sch-S и Sch-M – блокировки схемы.
Из режимов и типов блокировок, приведенных выше, можно создавать комбинации. Так, например, можно создать блокировку таблицы (TAB) в режиме «Х», то есть эксклюзивном. Это значит, что процесс запрашивает или получает эксклюзивную блокировку таблицы. Естественно, удержание такой блокировки на существенное время может привести к проблемам с блокировками.
В SQL Server есть хранимая процедура sp_lock, предоставляющая массу полезной для DBA информации о количестве и типах блокировок, запрошенных процессом.
Примечание: В SQL Server 2005 и выше эквивалентом sp_lock является DMV sys.dm_tran_locks.
На рисунке 9 показан результат выполнения sp_lock для SPID 51, Плохого Запроса.
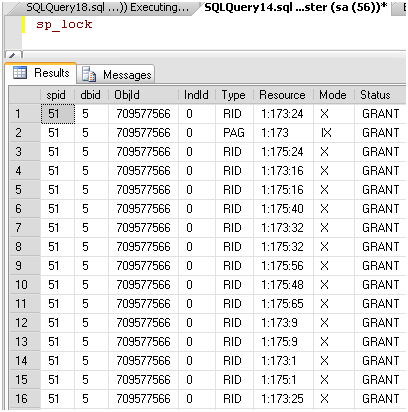
Рисунок 9. Блокировки Плохого Запроса.
Здесь вы можете видеть, что наложено много блокировок, в основном эксклюзивных блокировок уровня строки, как показывают режим "X" и тип "RID". Когда я вижу, один SPID, накладывающий такое количество блокировок, я понимаю, что что-то точно идет не так, как должно.
Часто простого подсчета блокировок и, что важнее, типов блокировок от отдельного SPID, достаточно, чтобы помочь мне обнаружить плохо выполняющийся запрос, даже если нет явного блокирования работы. Запрос блокировок, так же как и запрос подключений, расходуют память, и даже разделяемые блокировки, которые могут и не блокировать доступ к данным, иногда могут иметь большое влияние на производительность из-за нагрузки на память и другие ресурсы.
Автоматический поиск проблем
До этого момента мы использовали sp_who2 для поиска SPID, вызывающих проблемы с блокировками, DBCC INPUTBUFFER для извлечения SQL, исполняемого проблемным SPID и sp_lock для получения информации о блокировках, наложенных проблемным процессом. Ручное исполнение и анализ всего этого занимает некоторое время, а это время у вас не всегда будет.
Не хватает одного запроса, который рассказал бы сразу обо всем и сразу. Столкнувшись с такой необходимостью, я написал именно такой запрос. Он возвращает всю перечисленную выше информацию, и еще многое, в удобоваримом формате.
Если sp_who2 дает информацию, хорошую «на вид», мой запрос перекапывает нижележащую системную таблицу sysprocesses, чтобы получить дополнительную информацию о блокировках и блокирующих процессах.
Для sp_lock нижележащей системной таблицей является syslockinfo. Эта таблица не дает интуитивно понятной информации, в отличие от sysprocesses. В частности, типы блокировок приходится определять с помощью JOIN с таблицей spt_values из БД Master. При разработке запроса я решил что проще создать таблицу для хранения результатов sp_lock, а затем выполнять простой подсчет типов блокировок для каждого SPID.
Совет: Хранимая процедура sp_helptext – одна из тех «скрытых сокровищ», которые я за долгие годы использовал множество раз. Если передать ей любой объект, например, представление или хранимую процедуру, она отобразит код этого объекта. Запуск sp_lock через sp_helptext показывает join с таблицей spt_values.
В листинге 3 показан запрос, который одним махом находит и докладывает о блокирующих и заблокированных процессах, и о числе удерживаемых ими блокировок.
Листинг 3. Запрос, автоматизирующий поиск.
SET NOCOUNT ON
GO
Count the locks
IF EXISTS ( SELECT Name
FROM tempdb..sysobjects
WHERE name LIKE '#Hold_sp_lock%' )
DROP TABLE #Hold_sp_lock
GO
CREATE TABLE #Hold_sp_lock
(
spid INT,
dbid INT,
ObjId INT,
IndId SMALLINT,
Type VARCHAR(20),
Resource VARCHAR(50),
Mode VARCHAR(20),
Status VARCHAR(20)
)
INSERT INTO #Hold_sp_lock
EXEC sp_lock
SELECT COUNT(spid) AS lock_count,
SPID,
Type,
Cast(DB_NAME(DBID) as varchar(30)) as DBName,
mode
FROM #Hold_sp_lock
GROUP BY SPID,
Type,
DB_NAME(DBID),
MODE
Order by lock_count desc,
DBName,
SPID,
MODE
Show any blocked or blocking processes
IF EXISTS ( SELECT Name
FROM tempdb..sysobjects
Where name like '#Catch_SPID%' )
DROP TABLE #Catch_SPID
GO
Create Table #Catch_SPID
(
bSPID int,
BLK_Status char(10)
)
GO
Insert into #Catch_SPID
Select Distinct
SPID,
'BLOCKED'
from master..sysprocesses
where blocked <> 0
UNION
Select Distinct
blocked,
'BLOCKING'
from master..sysprocesses
where blocked <> 0
DECLARE @tSPID int
DECLARE @blkst char(10)
SELECT TOP 1
@tSPID = bSPID,
@blkst = BLK_Status
from #Catch_SPID
WHILE( @@ROWCOUNT > 0 )
BEGIN
PRINT 'DBCC Results for SPID ' + Cast(@tSPID as varchar(5)) + '( '
+ rtrim(@blkst) + ' )'
PRINT '
PRINT ''
DBCC INPUTBUFFER(@tSPID)
SELECT TOP 1
@tSPID = bSPID,
@blkst = BLK_Status
from #Catch_SPID
WHERE bSPID > @tSPID
Order by bSPID
END
|
В этом запросе нет ничего особо сложного. Это главная стартовая точка, откуда вы можете быстро анализировать проблемы блокировок в SQL Server. В случае неблокирующих блокировок он покажет все запросы, представляющие потенциальную проблему из-за потребления таких ресурсов как память и I/O.
На рисунке 10 показан результат выполнения этого запроса во время исполнения «Плохого Запроса».
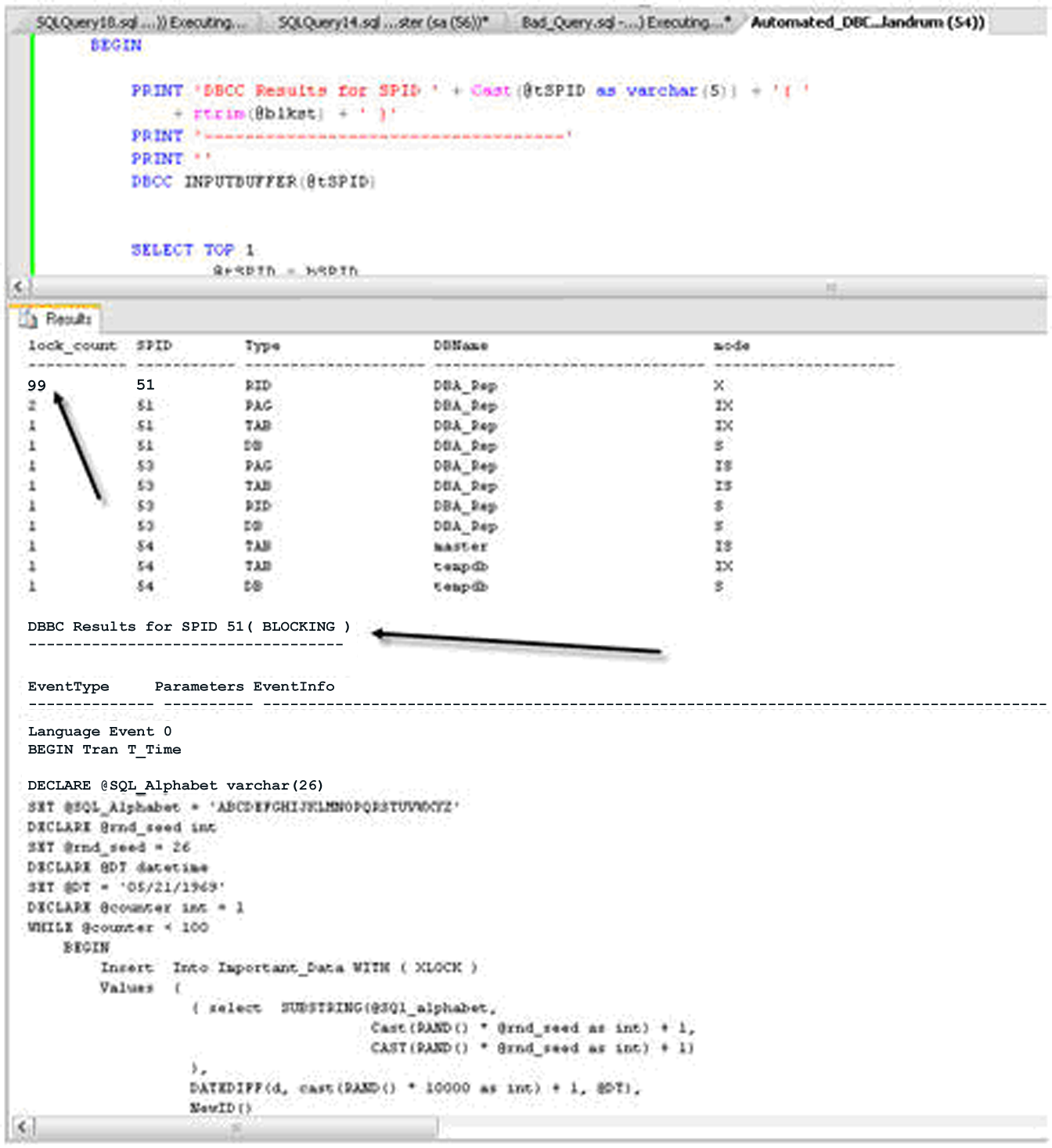
Рисунок 10. Результат подсчета блокировок и блокирующий запрос в результатах Automated Discovery.
Обратите внимание на высокое число блокировок у SPID 51, обвиняемого запроса. Следующий раздел результата показывает, что в данном случае SPID 51 на самом деле вызывает блокировку, следом идет код, исполняемый SPID, который мы уже видели в результате DBCC INPUTBUFFER.
Кроме того, Automated Discovery Query также перечисляет все заблокированные SPID. На рисунке 11 показаны запросы, в данном случае простые SELECT из таблицы Important_Data, которые заблокированы SPID 51.
Вы можете решить, что неплохо бы взять этот запрос и сохранить как хранимую процедуру. Затем его можно поместить во все БД поддержки на каждом сервере, чтобы всегда иметь под рукой. Это также означает, что вы сможете параметризовать его, чтобы управлять его поведением. Например, вы можете решить, что не хотите исполнять часть запроса, подсчитывающую блокировки, которая на очень загруженной системе может занять немало времени.
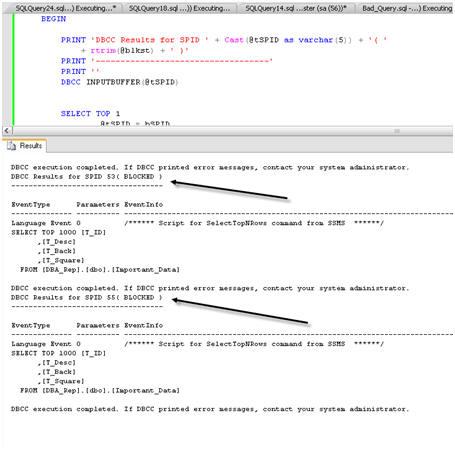
Рисунок 11. Запрос Automated Discovery нашел заблокированные SPID.
В листинге 4 показан код создания этой хранимой процедуры, usp_Find_Problems, с флагом, служащим для исполнения части запроса, подсчитывающей блокировки, в случае надобности.
Листинг 4. Код usp_Find_Problems.
USE [DBA_Rep]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[usp_Find_Problems] ( @count_locks BIT = 1 )
AS
SET NOCOUNT ON
IF @count_locks = 0
GOTO Get_Blocks
ELSE
IF @count_locks = 1
BEGIN
CREATE TABLE #Hold_sp_lock
(
spid INT,
dbid INT,
ObjId INT,
IndId SMALLINT,
Type VARCHAR(20),
Resource VARCHAR(50),
Mode VARCHAR(20),
Status VARCHAR(20)
)
INSERT INTO #Hold_sp_lock
EXEC sp_lock
SELECT COUNT(spid) AS lock_count,
SPID,
Type,
CAST(DB_NAME(DBID) AS VARCHAR(30)) AS DBName,
mode
FROM #Hold_sp_lock
GROUP BY SPID,
Type,
CAST(DB_NAME(DBID) AS VARCHAR(30)),
MODE
ORDER BY lock_count DESC,
DBName,
SPID,
MODE
Get_Blocks:
CREATE TABLE #Catch_SPID
(
bSPID INT,
BLK_Status CHAR(10)
)
INSERT INTO #Catch_SPID
SELECT DISTINCT
SPID,
'BLOCKED'
FROM master..sysprocesses
WHERE blocked <> 0
UNION
SELECT DISTINCT
blocked,
'BLOCKING'
FROM master..sysprocesses
WHERE blocked <> 0
DECLARE @tSPID INT
DECLARE @blkst CHAR(10)
SELECT TOP 1
@tSPID = bSPID,
@blkst = BLK_Status
FROM #Catch_SPID
WHILE( @@ROWCOUNT > 0 )
BEGIN
PRINT 'DBCC Results for SPID '
+ CAST(@tSPID AS VARCHAR(5)) + '( ' + RTRIM(@blkst)
+ ' )'
PRINT '
PRINT ''
DBCC INPUTBUFFER(@tSPID)
SELECT TOP 1
@tSPID = bSPID,
@blkst = BLK_Status
FROM #Catch_SPID
WHERE bSPID > @tSPID
ORDER BY bSPID
END
END
|
Исполнение usp_Find_Problems без параметров возвращает число блокировок, а также блокированные и блокирующие SPID, при использовании входящего параметра 0 число блокировок не подсчитывается
Итоги
В этой статье я показал, как я выявляю проблемы с блокировками, возникающие в SQL Server. Это хорошее начало для DBA-детектива, но это только начало. Я только мельком упоминал CPU и I/O в этой статье, говоря о проблемном коде. В своей книге я иду дальше в анализе проблем производительности, в частности, там рассказано, как организовать немедленное оповещение об этих и других проблемах.
Наконец, если вы не знаете о проблеме, вы не можете ее устранить. Я предпочту получить оповещение о потенциальной проблеме от системы, отслеживающей такие события, а не от разъяренного пользователя приложения или от техподдержки. Конечно, пользователи вас завалят письмами, но это ничего, они все понимают. Это их начальство не понимает. Если вы сможете обнаружить и устранить, или просто сообщить о проблеме раньше всех, это покажет, что вы работаете с опережением. А вы ... вы, в конце концов, DBA.
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы
то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских
прав.
Copyright � 1994-2016 ��� "�-�����"